5. スーパーコンピュータAOBA-Aの高速化の概要¶
スーパーコンピューティング研究部 滝沢寛之 高橋慧智 下村陽一
情報部デジタルサービス支援課 大泉健治 小野敏 山下毅 齋藤敦子 森谷友映
高性能計算技術開発(NEC)共同研究部門 撫佐昭裕 磯部洋子 曽我隆 山口健太
日本電気株式会社 加藤季広
5.1. ベクトル処理による高速化¶
5.1.1. ベクトル処理の概要¶
変数や配列の各要素のことをスカラデータとよぶ.これに対して,行列の行要素や列要素など規則的に並んだデータ列のことをベクトルデータとよぶ.スカラ処理は,スカラデータを1つずつ処理する(スカラ命令)のに対して,ベクトル処理では1つの実行命令で,規則的に並んだ複数の配列データ(ベクトルデータ)に対して同時に演算を行う(ベクトル命令)ことができる.図 5.1.1‑1に,スカラ命令とベクトル命令の動作のイメージ図を記載する.図の左側にDOループのコードイメージを記載しているが,このDOループはA(I)=B(I)+C(I),D(I)=E(I)+F(I)の2つの計算式を200回繰り返す.このDOループをスカラ命令で処理する場合,図の右側の上のように,まずは,I=1の場合について,B(1)+C(1)の計算を行い,次にE(1)+E(1)の計算を行う.I=1の計算が完了すると次にI=2の場合の処理としてB(2)+C(2), E(2)+F(2)の計算を行うというように,DOループの繰り返し変数Iが200になるまで逐次的に実行する.一方で,同じDOループをベクトル命令で実行する場合,ループ変数 Iが1~200 について1回のベクトル命令で計算することができるため,スカラ命令に比べて高速に計算することができる.なお,AOBA-Aに搭載されたベクトルプロセッサの場合,一度のベクトル命令で処理可能な要素数は最大256要素である.そのため,ループ長200のループの場合,B(I)+C(I) および E(I)+F(I)の計算はそれぞれ1回のベクトル命令で実行される.AOBA-Aの性能を十分に引き出すためには,なるべく多くの処理をベクトル命令で実行する必要がある.
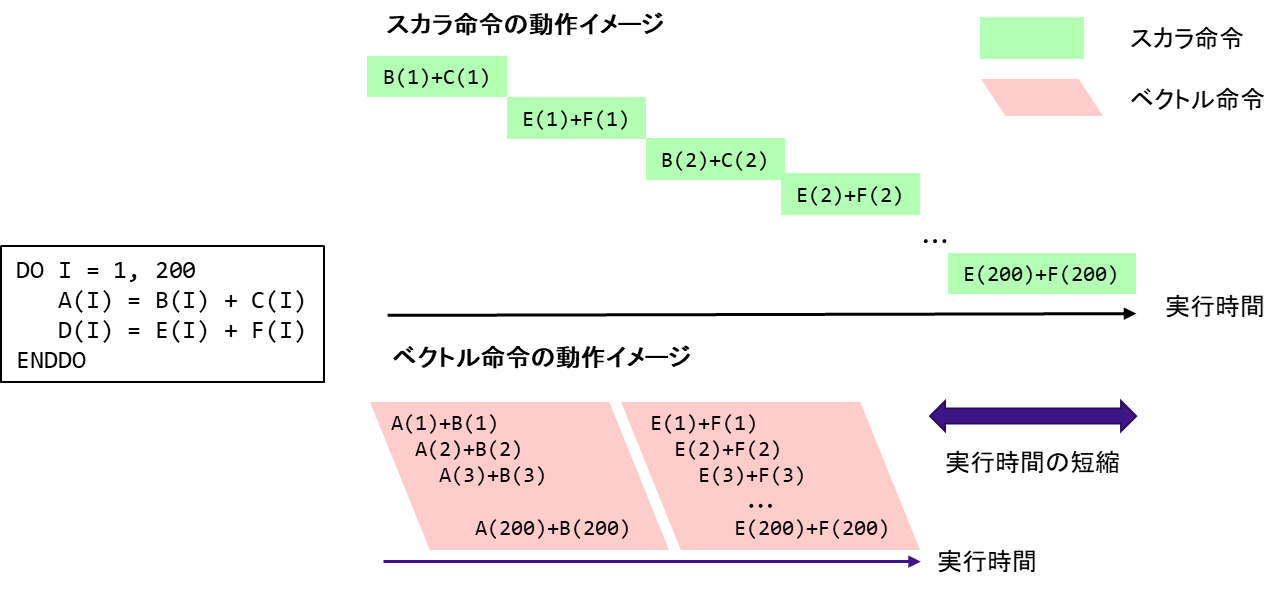
図 5.1.1‑1 スカラ命令とベクトル命令の動作のイメージ図¶
5.1.2. ベクトル化率¶
プログラムを実行する場合,一般的にはプログラム中の全ての処理をベクトル処理として実行することは難しい.例えば,計算に必要なデータを読み込んだり,計算結果を書き出したりする入出力処理を含むループや,ループ内の計算が計算順番に依存している(計算順番が変わると計算結果が変わる)ようなループは,ベクトル命令が適用できないためスカラ処理となる.ベクトル化率(vector processing rate)とは,プログラムがどのくらいベクトル処理されているかを示す指標であり,あるプログラムをすべてスカラ処理で実行したときの総実行時間に対して,ベクトル処理が可能な部分の実行時間の割合をあらわす.図 5.1.2‑1にプログラムの実行時間の概念図を示す.
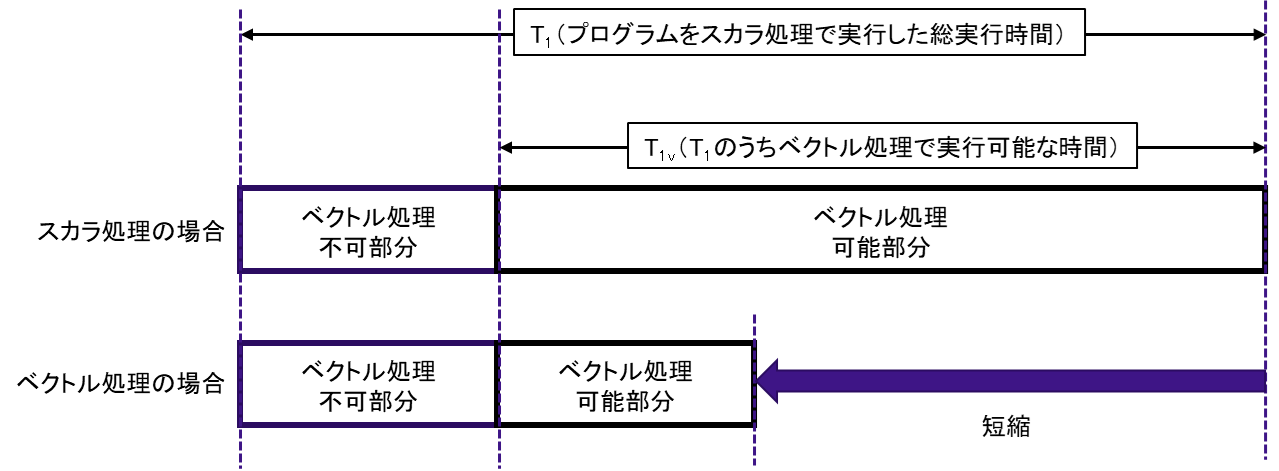
図 5.1.2‑1 プログラムの実行時間の概念図¶
プログラム全体をスカラ処理で実行した時間をT1,そのうち,ベクトル処理で実行可能な時間をT1vとすると,ベクトル化率αは次式で定義される.
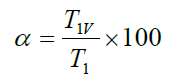
ベクトル処理による性能向上比Pは,スカラ処理性能とベクトル処理性能の比をβとすると以下の式であらわすことができる.
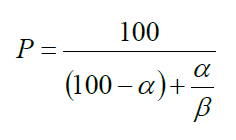
この関係式をアムダールの法則とよび,図 5.1.2‑2はベクトル化率と性能向上の関係をあらわしている.この図から,高い性能向上を実現するためには,ベクトル化率をできるだけ100% に近づけることが非常に重要であることがわかる.
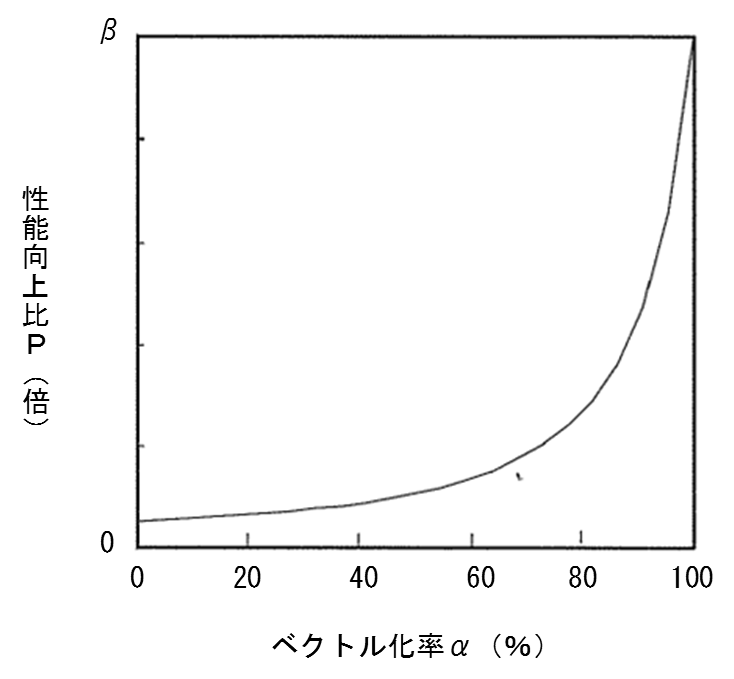
図 5.1.2‑2 ベクトル化率と性能向上比の関係(アムダールの法則)¶
ベクトル化率を調べるためにはプログラムをすべてスカラ処理で実行した場合と,ベクトル処理可能な部分をベクトル化して実行した場合の実行時間が必要であるが,これらの時間は同時に得ることはできないためベクトル化率を容易に算出することは難しい.そこで,AOBA-Aではベクトル化率の代わりにベクトル演算率(vector operation ratio)という指標を使用する.ベクトル演算率は,プログラムで処理される全演算要素数に対するベクトル処理される演算要素数の割合で算出され,ほぼベクトル化率とみなせる指標である.なお,AOBA-Aで利用可能な性能解析ツールを使用することで,利用者は容易に自分のプログラムのベクトル演算率を確認することができる.
5.1.3. ベクトル長¶
ベクトル化対象のループの繰り返し回数のことをベクトル長(ループ長)と呼ぶ.AOBA-Aでは1回のベクトル命令で最大256要素のベクトル処理を行うことができる.例えば,図 5.1.3‑1のような計算があった場合,a(i) + b(i) の計算は,2回のベクトル命令で実行可能である.1回目のベクトル命令で256要素同士の足し算を行い,2回目のベクトル命令で残りの44要素同士の足し算を行う.1回のベクトル命令で行った演算要素数の平均値を平均ベクトル長(average vector length)と呼び,この値はベクトル処理が効率的に行われているかを判断するのに重要な指標である.この例における平均ベクトル長は150(=(256+44)/2)となる.ループ長が長くなればなるほど,平均ベクトル長は最大値の256に近づくため,できるだけベクトル化対象ループのループ長を長くすることが重要である.
do i=1,300
a(i)=a(i)+b(i)
enddo
図 5.1.3‑1 ループ例
ループ処理をベクトル化することで,必ず性能が向上するとは限らない.例えば,ループ長が非常に短いループをベクトル化した場合,逆に性能が悪化する場合もある.これには,ベクトル処理の立ち上がり時間が関係している.ループをベクトル処理する場合,ベクトル処理が開始されるまで少し時間がかかり,これを立ち上がり時間とよぶ.図 5.1.3‑2はループ処理をベクトル化した場合としない場合のループ長と実行時間の関係を示している.ベクトル処理した場合,ループ長が短いところでは,立ち上がり時間の影響でベクトル化しない場合の性能が高くなっていることがわかる.ベクトル化した場合としない場合とで実行時間が同じになるループ長のことを交差ループ長と呼び,ループ長が交差ループ長(3程度)より短い場合には,ベクトル化することで性能が悪化してしまう場合がある.逆に,ループ長が長ければ長いほど,ベクトル化した場合の効果は大きくなるため,この図からもループ長を長くすることの重要性がわかる.
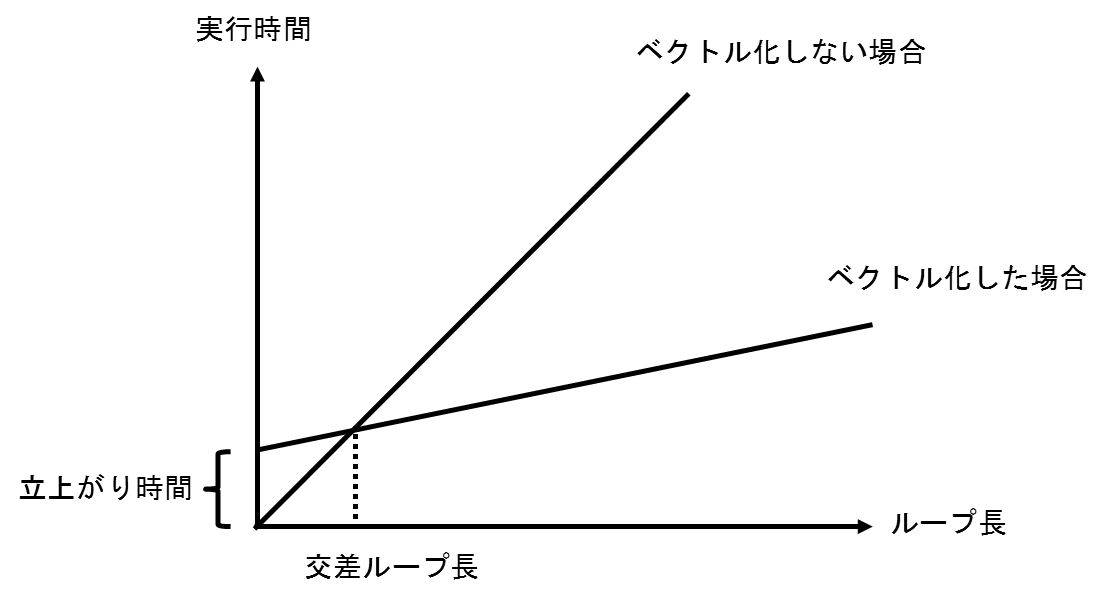
図 5.1.3‑2 交差ループ長¶
5.2. 並列処理による高速化¶
5.2.1. 並列化の概要¶
並列処理とは,プログラム内の処理を分割し,複数のコアを使用して同時に実行することである.図 5.2.1‑1に並列処理の概念図を示す.1コアで実行したときに最も時間がかかる処理Bが並列化可能だった場合,4つのコアに処理を分割して並行して実行することで,プログラムの終了までの経過時間を短縮することができる.並列処理モデルには大きく分けて「共有メモリ並列」と「分散メモリ並列」の方式がある.
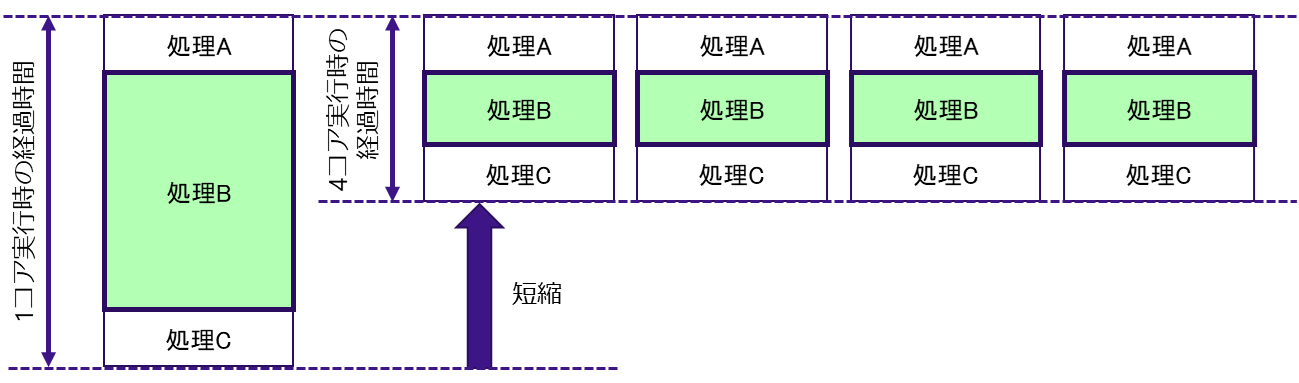
図 5.2.1‑1 並列処理の概念図¶
5.2.2. 共有メモリ並列¶
共有メモリ並列とは,複数のコアが単一のメモリ空間を共有しながら並列処理を行うものである.図 5.2.2‑1に,共有メモリ並列の概念図を示す.AOBA-Aでは,Vector Engine(VE)ごとに共有メモリが搭載されており,8つのベクトルコアにより共有されている.つまり,共有メモリ並列処理はVE単位で実行され,最大並列数は8並列となる.並列化手法としては,自動並列およびOpenMP並列が利用できる.
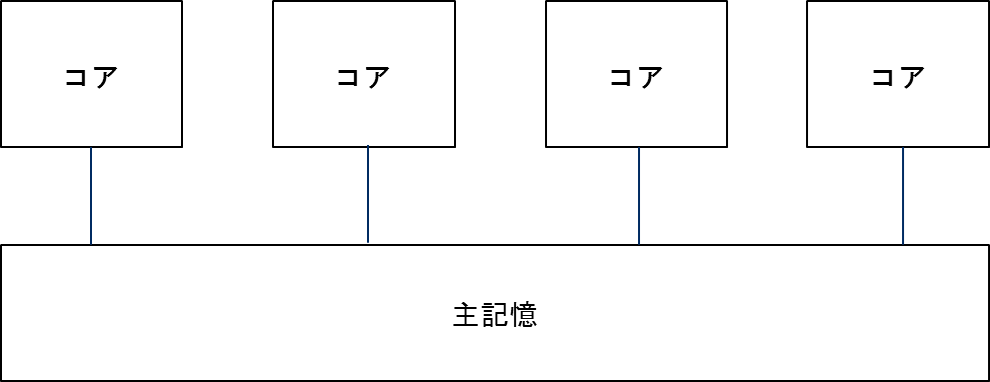
図 5.2.2‑1 共有メモリ並列¶
(1) 自動並列¶
AOBA-Aのコンパイラは自動並列化機能を有している.自動並列化機能を使用することで,コンパイラが自動的にプログラム内の並列実行できるループや文の集まりを抽出し,並列処理できるようにプログラムを変形する.さらに,並列処理制御のための処理の挿入などを自動的に行う.自動並列化を有効にするためには,コンパイル時に「-mparallel」オプションを指定する(Fortranプログラム/Cプログラム共通).図 5.2.2‑2にFortranプログラムにおけるコンパイルオプションの指定例を記載する.
# Fortranプログラム
$ nfort -mparallel -O3 a.f90
図 5.2.2‑2 自動並列コンパイルオプション指定例
(2) OpenMP並列¶
コンパイラが自動的に並列処理を行う自動並列に対して,OpenMP並列による並列化を行う場合,ユーザ自身が並列化のための指示行をプログラム中に挿入する必要がある.自動並列化は,コンパイラの実装に依存するため,コンパイラ環境が変わることで並列化の挙動も変わる可能性があるが,OpenMPは標準規格であるため,異なるアーキテクチャのシステムでもソースコードを書き換える必要がなく,ユーザが意図したとおりの並列化を実現することができる.OpenMP指示行を有効にするためには,コンパイル時に「-fopenmp」オプションを指定する(Fortranプログラム/Cプログラム共通).図 5.2.2‑3にFortranプログラムにおけるコンパイルオプションの指定例を記載する.
# Fortranプログラム
$ nfort -fopenmp -O3 a.f90
図 5.2.2‑3 OpenMP並列コンパイルオプション指定例
図 5.2.2‑4にOpenMP並列の基本構造を記載する.Fortranの場合,「!$OMP PARALLEL」と「!$OMP END PARALLEL」で囲まれた範囲の処理を複数のスレッドで実行する.Cプログラムの場合,「#pragma omp parallel」の次のブロック(”{“ から “}” まで)の処理が並列化の対象となる.
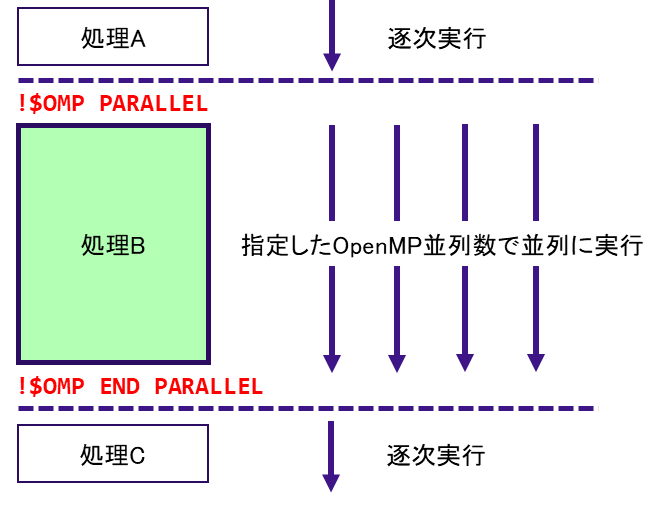
図 5.2.2‑4 OpenMP並列の基本構造¶
OpenMP並列化を行う際には,並列化対象のループ内だけで定義・参照される配列や変数の取り扱いに注意する必要がある.図 5.2.2‑5の例のようなプログラムを,一番外側のループ(ループ変数k)でOpenMP並列化する.この場合,ループ内で使用される配列aはkの次元を持たず,さらにループ内で定義・参照されている.もし,配列aのメモリ領域がすべてのスレッドで共通の領域であった場合,複数のスレッドから同じ領域に対して定義(値の更新)が行われるため,そのデータを参照するタイミングによって結果が変わってしまう可能性がある.つまり,スレッドごとに別々のメモリ領域を確保しなければ本来の正しい結果を得ることはできない.このような場合にはPRIVATE宣言を行うことで,特定の配列,変数をスレッドごとに独立したメモリ領域に確保することができる.PRIVATE宣言の指定例を図 5.2.2‑6に記載する.
do k = 1, nz
do j = 1, ny
do i = 1, nx
a(i,j) = b(i,j,k)*c(i,k)
d(i,j,k) = d(i,j,k)+a(i,j)*e(j,k)
enddo
enddo
enddo
図 5.2.2‑5 OpenMP化するサンプルプログラム
!$OMP PARALLEL DO PRIVATE(a)
do k = 1, nz
do j = 1, ny
do i = 1, nx
a(i,j) = b(i,j,k)*c(i,k)
d(i,j,k) = d(i,j,k)+a(i,j)*e(j,k)
enddo
enddo
enddo
!$OMP END PARALLEL DO
図 5.2.2‑6 PRIVATE宣言の指定例
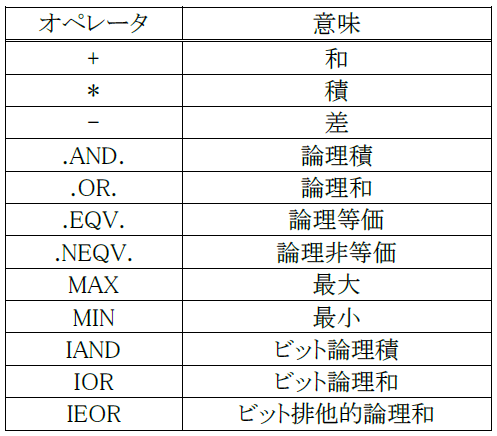
総和演算などの処理を並列化して実行する場合にも注意が必要である.図 5.2.2‑7に総和演算の例を記載する.この処理を並列化する場合,スレッドことに部分和の計算結果を変数sumに代入し,最後に部分和同士を足し合わせて総和を求める必要がある.このとき,変数sumがすべてのスレッドで共通のメモリ領域だった場合,正しく部分和を計算することができず,正しい結果を得ることはできない.このような場合には,リダクション演算を使用する.図 5.2.2‑8にリダクション演算の指定例を示す.
リダクション演算では,総和演算のほかにも表 5.2.2‑1に記載されているような演算子や組み込み関数が実行可能である.
do i=1,n
sum=sum+i
enddo
図 5.2.2‑7 総和演算を行うサンプルプログラム
!$OMP PARALLEL DO REDUCTION(+:sum)
do i=1,n
sum=sum+i
enddo
!$OMP END PARALLEL DO
図 5.2.2‑8 OpenMPでのリダクション演算の指定例
表 5.2.2‑1 リダクション演算で指定可能な演算子,組み込み関数
5.2.3. 分散メモリ並列¶
自動並列・OpenMP並列がメモリを共有するコアによる並列化であるのに対して,分散メモリ並列はネットワークを介して接続された独立したメモリ空間をもつ複数のノード間で行うことができる並列化である.図 5.2.3‑1に,分散メモリ並列の概念図を示す.共有メモリ並列がVE内での並列化であったのに対して,分散メモリ並列では複数のVEを使用して並列化を行うことができる.分散メモリ並列を実現するための並列プログラミング環境としてMPI(Message Passing Interface)がある.MPIは分散メモリ並列計算の標準規格となっているためポータビリティに優れているが,ユーザ自身でデータや処理を分割し,プロセス間の通信の方法やタイミングをプログラミングする必要がある.
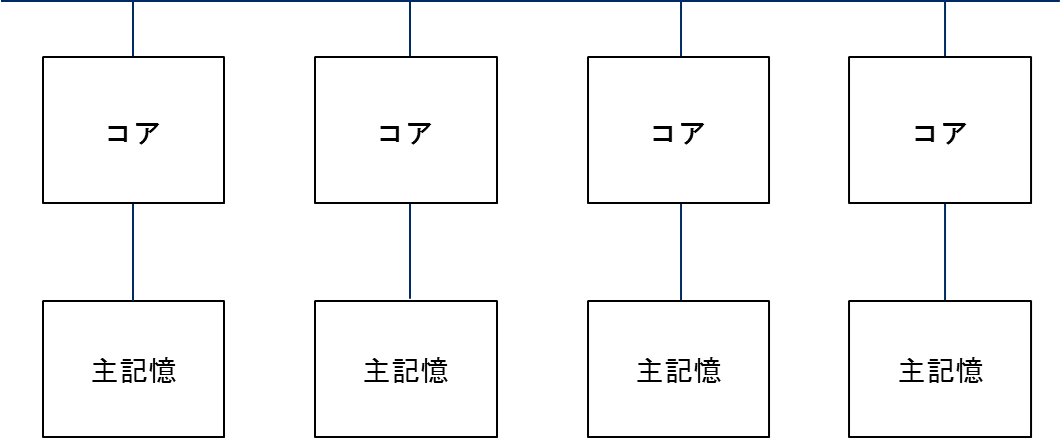
図 5.2.3‑1 分散メモリ並列¶
(1) MPIプログラムの基本構造¶
6図 5.2.3‑2にMPIプログラムの基本構造の概念図を記載する.MPI化の対象となるのはプログラム内でMPI_INITが呼び出された地点からMPI_FINALIZEが呼び出された地点までとなる.プログラム実行時の全プロセス数は MPI_COMM_SIZE により確認することができる.また,自分自身のプロセス番号は MPI_COMM_RANKにより得ることができる.

図 5.2.3‑2 MPIプログラムの基本構造¶
(2) 1対1通信¶
MPIでは,それぞれのプロセスは独立したメモリ空間をもっているため,ほかのプロセスが更新したデータを使用して計算を行う必要がある場合,データを更新したプロセスが持っているデータを自分自身のメモリ空間にコピーして計算を行う必要がある.このとき,プロセス間通信が発生する.通信は1対1通信と集団通信に分類することができる.
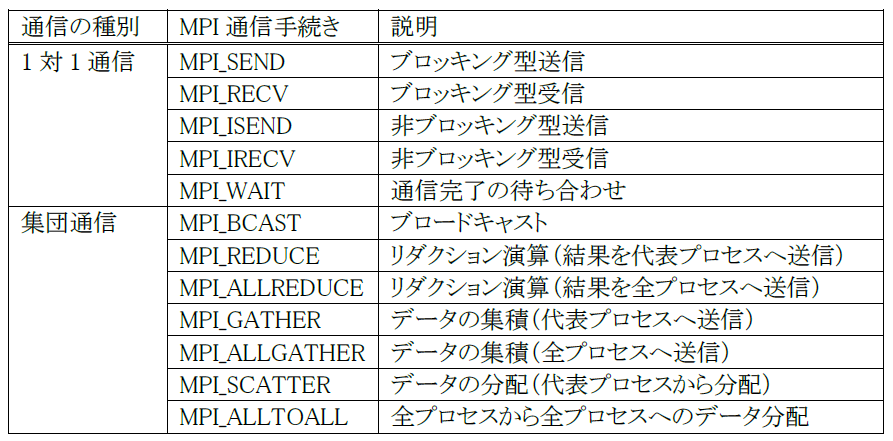
図 5.2.3‑3に1対1通信の概念図を記載する.プロセス0のデータをプロセス1に転送する,プロセス1のデータをプロセス2に転送するというように,1対1通信は一組の送信プロセスと受信プロセスが行うデータ転送であり,代表的なものとしてMPI_SEND,MPI_RECVがある.図 5.2.3‑4はMPI_SENDとMPI_RECVの通信の動作を模式的にあらわしたものであり,プロセス0がもつ配列の一部をプロセス1に転送している.表 5.2.3‑1に代表的な1対1通信の例を記載する.
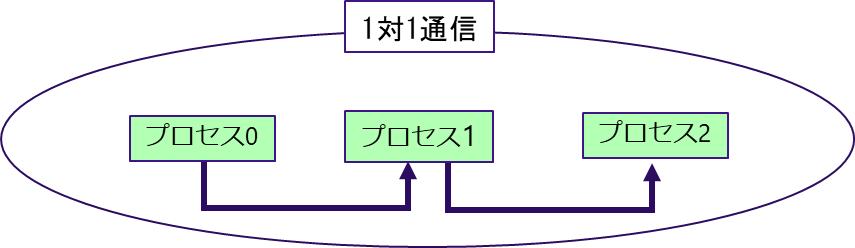
図 5.2.3‑3 1対1通信の概念図¶
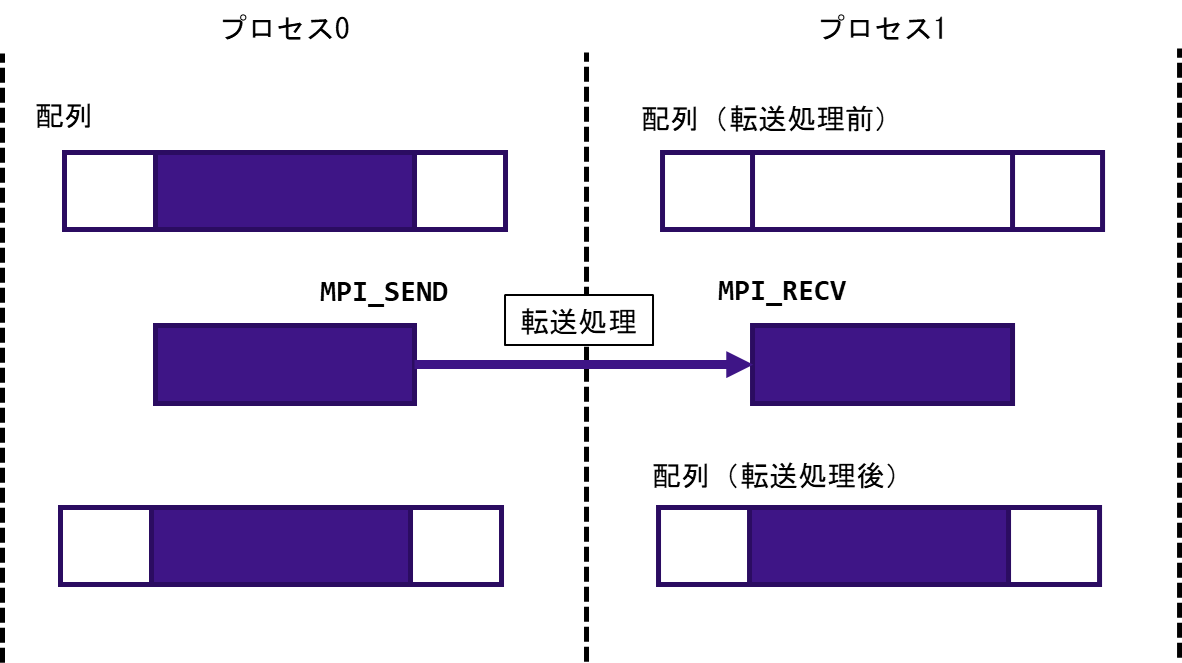
図 5.2.3‑4 MPI_SEND,MPI_RECVの動作の模式図¶
(3) 集団通信¶
1対1通信が特定の1プロセスとの間で行われるデータ転送であるのに対し,同じコミュニケータを持つ全プロセスで行う同期的通信を集団通信と呼ぶ.図 5.2.3‑5に集団通信の概念図を記載する.プロセス1とプロセス2のデータをプロセス0に集めるといったようにグループ内のプロセス全体でデータのやり取りを行う.代表的な集団通信としてMPI_REDUCEがある.図 5.2.3‑6はMPI_REDUCEの通信の動作を模式的にあらわしたものである.MPI_REDUCEは,同じコミュニケータを持つ全プロセスが,送信バッファのデータを通信しながら指定された演算を行い,演算結果を指定されたプロセスの受信バッファに格納する.指定可能な演算として総和,最大値/最小値探索,累積などがある.この例では,最大値探索を行っており,結果をプロセス0の受信バッファに格納している.プロセス0からプロセス3がもつデータの中で,最大の値がプロセス0の受信バッファに格納されていることがわかる.集団通信には,ほかにも,代表プロセスの送信バッファのデータを全プロセスの受信バッファに送信するMPI_SCATTERや,逆に全プロセスの送信バッファから代表プロセスの受信バッファにデータを集めるMPI_GATHERなどもある.表 5.2.3‑1に代表的な集団通信の例を記載する.
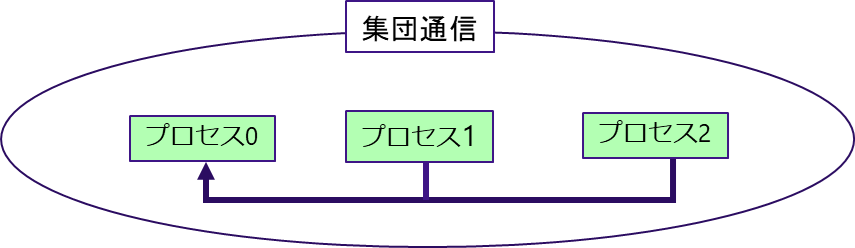
図 5.2.3‑5 集団通信の概念図¶
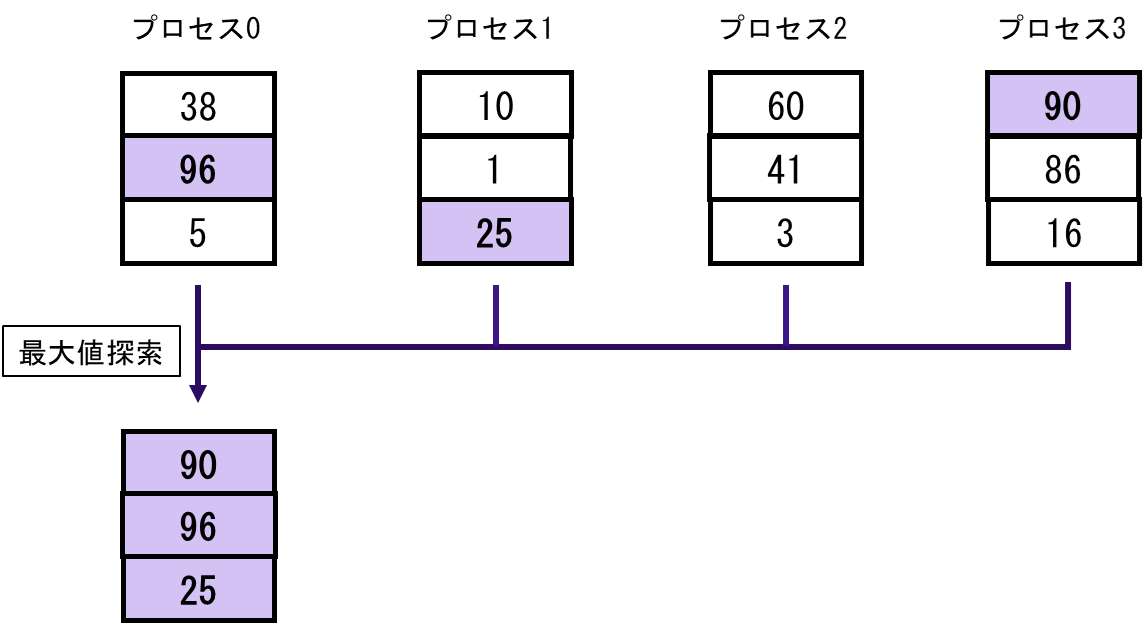
図 5.2.3‑6 MPI_REDUCE(最大値探索)の動作の模式図¶
表 5.2.3‑1 代表的なMPI通信手続き
5.3. VH-VE連携による高速化¶
第3章に記載のとおり,AOBA-Aを構成するSX-Aurora TSUBASAは汎用的なx86プロセッサ(AMD EPYC CPU)を搭載したVHとベクトルプロセッサを搭載したVEから構成される.このヘテロジニアスなHW構成を活用することで,AOBA-Aでは3つのプログラミングモデルから最適なものを選択することができる.図 5.3‑1は,AOBA-Aで実現可能な3つのプログラミングモデルを模式的に記載したものである.
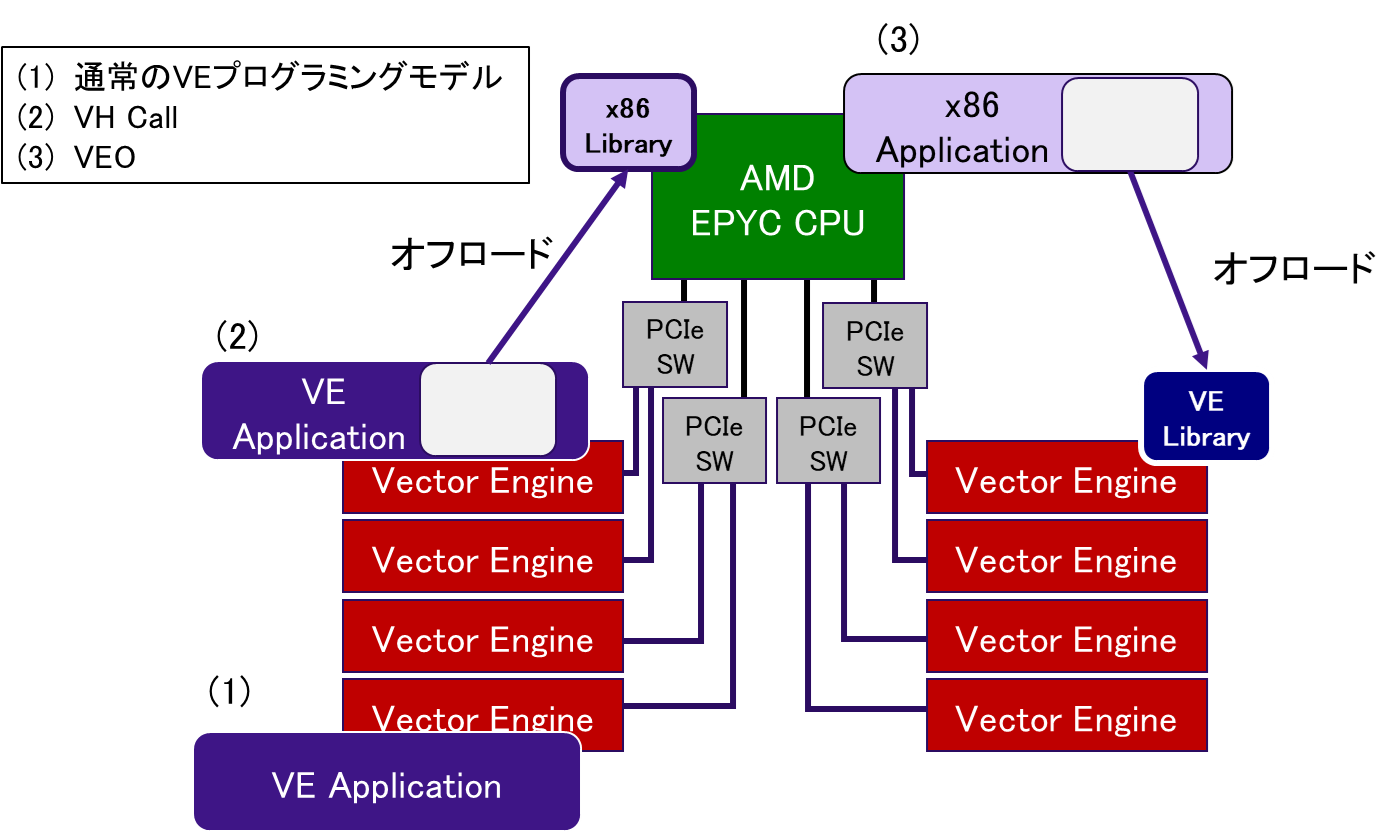
図 5.3‑1 AOBA-Aの実行モデル¶
(1)の実行モデルは,通常のVEプログラミングモデルである.ユーザアプリケーションをSX-Aurora TSUBASA向けコンパイラでコンパイルすることで,アプリケーション全体をVE上で実行することができる.プログラム全体をVEで実行したときに,一部の処理がベクトル化できず,その部分が性能のボトルネックとなる場合がある.そのような場合に,アプリケーションの一部をx86プロセッサ側にオフロードして実行する実行モデルが (2) のVH Callである※1.一方,実行モデル (3) のAlternative VE Offloading (VEO) は,GPGPUなどのアクセラレータで使用される実行モデルであり,x86アプリケーションからVEカーネル関数を呼び出すことが可能である※2.このように,実行モデル(2)(3)では,VHとVEがお互いの短所を補い合うことで,より高速にアプリケーションを実行できるようになる.
また,SX-Aurora TSUBASAでは,VE上で動作するMPIプロセスとVH上で動作するMPIプロセスを連携実行させるScalar-Vector Hybrid(ハイブリッド実行)が可能である.図 5.3‑2にハイブリッド実行の模式図を記載する.
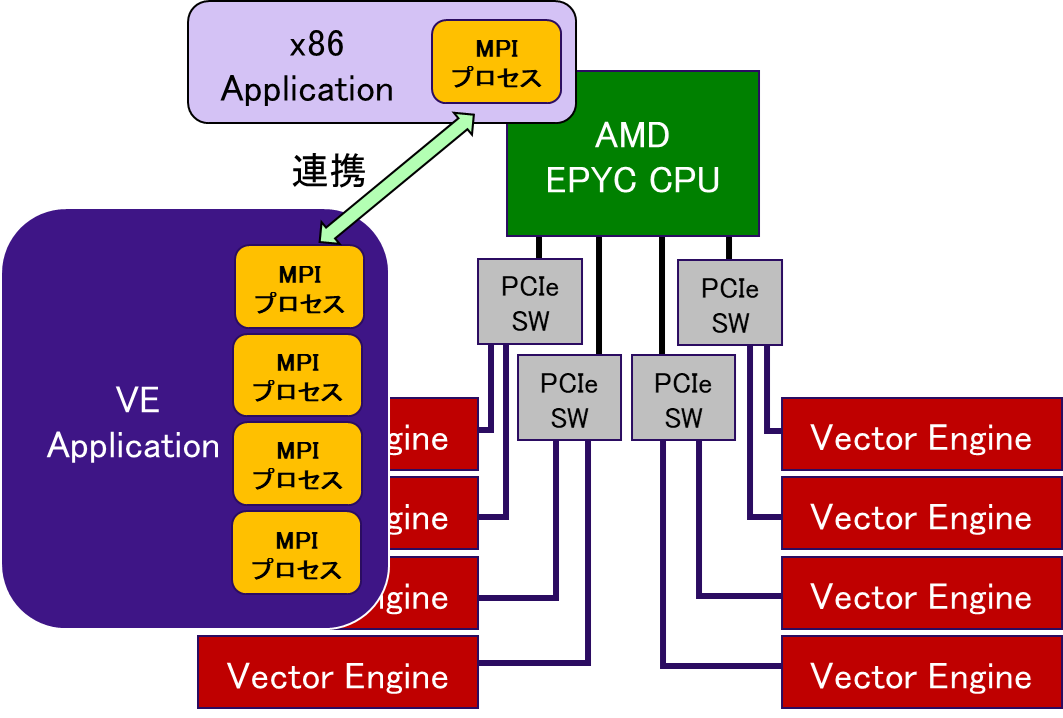
図 5.3‑2 Scalar-Vector Hybrid の模式図¶
ハイブリッド実行が有効なケースとして,定期的に大容量のI/O処理が発生するような場合が考えられる.VEはメモリ負荷の高い演算処理が得意である一方で,I/O処理に関してはVHで実行したほうが高速に処理できる場合が多い.そこで,演算処理をVEのMPIプロセスで実行し,I/O処置についてはVH側のMPIプロセスが実行することで,VHとVEの両者の長所を生かすことができる.VH Callを使用することでも,演算処置とI/O処理をVHとVEで分けて実行することは可能であるが,VH Callの場合には,VH側のI/O処理が終了するまで,VE側の演算処理は待ち状態となる.一方で,ハイブリッド実行の場合には,演算処置とI/O処理をオーバーラップして実行することができるため,より高速に実行できる.
※1 https://sxauroratsubasa.sakura.ne.jp/documents/veos/en/libsysve/md_doc_VHCall.html
※2 https://sxauroratsubasa.sakura.ne.jp/documents/veos/en/aveo/index.html
5.3.1. VH Call¶
VH Callにより,VEが不得意とする処理をVH側にオフロードすることができる.VH Callを利用するためには,はじめにVH側にオフロードする処理を共有ライブラリとして作成しておく必要がある.オフロードする処理をプログラムとして切り出し,VH用のコンパイラを使用して共有ライブラリを作成する.作成した共有ライブラリをVE側で動作するプログラムから呼び出すことで,VH上に処理をオフロードすることができる.VH CallではVEおよびVHで動作するプログラム,共有ライブラリはFortranとC言語の両方をサポートしている.
表 5.3.1‑1は,VE側で動作するFortranプログラムからVH上で動作する共有ライブラリを呼び出す手順の概要をまとめたものである.
表 5.3.1‑1 VH Callの利用手順

まず,vhcall_installを使用して,あらかじめ作成しておいた共有ライブラリを呼び出す.次に,fvhcall_findにより,呼び出した共有ライブラリに含まれる手続きの中から,今回呼び出す手続きを探す.次に,fvhcall_args_allocにより,引数のバッファを確保し,fvhcall_args_setで引数の値を設定する.VH側の処理の呼び出しは,fvhcall_invoke_with_argsにより行う.この呼び出しにより,VH上で処理が行われる.VH側の処理が完了したら,fvhcall_args_freeおよびfvhcall_uninstall により後処理を行う.
5.3.2. VEO¶
VEOにより,x86アプリケーションの処理の一部をVE側にオフロードする.VEOを利用する場合も,最初にVE側にオフロードする処理を切り出し,VE用のコンパイラでコンパイルしておく必要がある.VEOは,実行ファイルや共有ライブラリに含まれる関数をサポートするため,どちらかの形式で準備しておく.VEOでは,VE上で動作する実行ファイル,共有ライブラリについてはFortranとC言語の両方をサポートしているが,VH上で動作するプログラムはC言語のみがサポートされている.
表 5.3.2‑1は,VH側で動作するCプログラムからVE上で動作する実行ファイルもしくは共有ライブラリを呼び出す手順の概要をまとめたものである.
表 5.3.2‑1 VEOの利用手順

VH Callとの違いは,手順1,3でVE上で動作するプロセス,スレッドを生成する必要があることである.また,VEOの場合には,VE上で実行する関数を非同期で呼び出すことが可能である.そのため手順6のveo_call_wait_resultによりVE上で実行した関数の終了を待ち,戻り値を受け取る.
5.3.3. Scalar-Vector Hybrid¶
ハイブリッド実行を行うことで,VE上で動作するMPIプロセスとVH上で動作するMPIプロセスを連携して実行させることができる※3.MPIプロセス間の通信は,同じコミュニケータに所属するプロセス同士で行われるため,VE上のMPIプロセスとVH上のMPIプロセスが通信するためのコミュニケータを準備し,VE-VH間でのデータの転送を行う.図 5.3.3‑1は,ハイブリッド実行時のコミュニケータの例を示している.
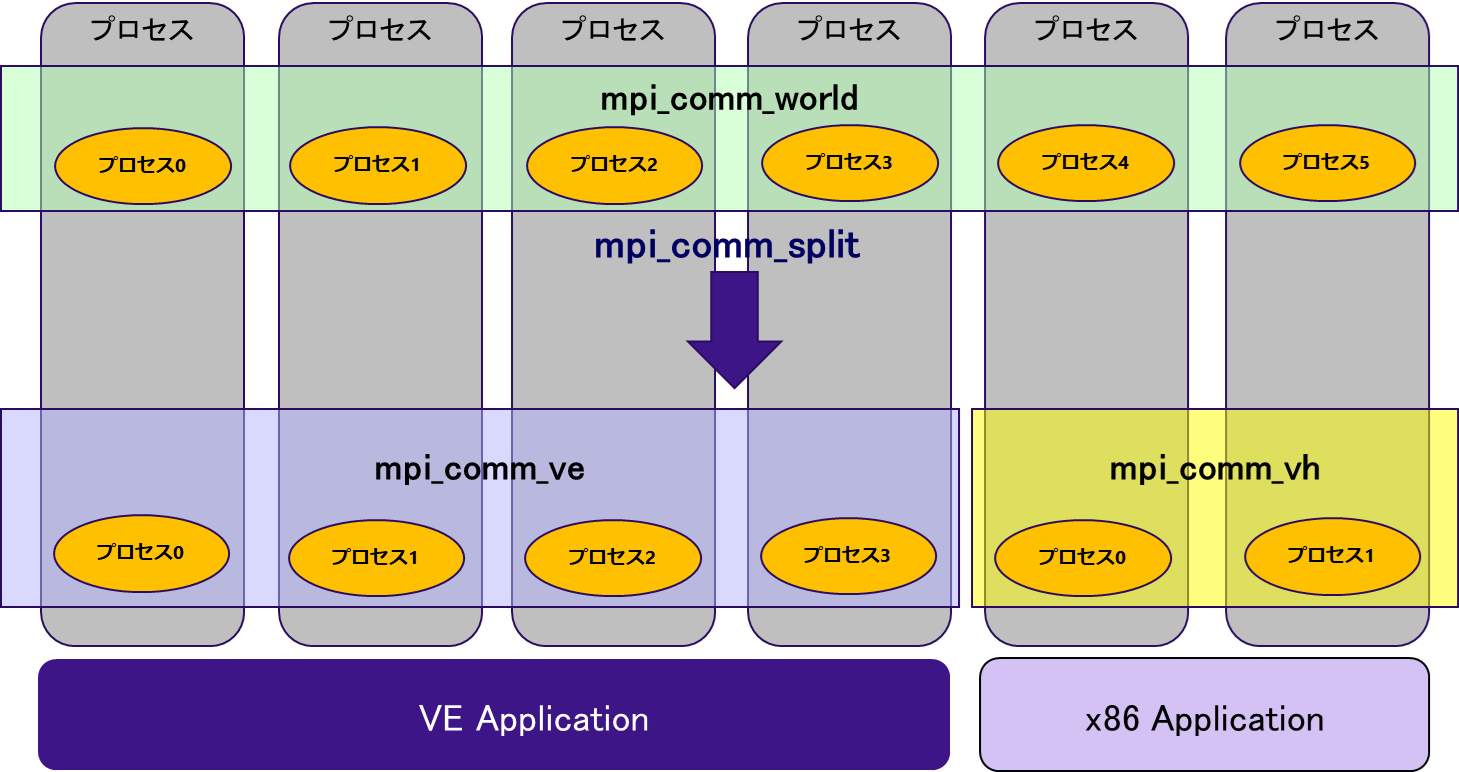
図 5.3.3‑1 Scalar-Vector Hybrid のコミュニケータの分割例¶
この例では,VE上のMPIプロセス間通信のためのコミュニケータ(mpi_comm_ve)と,VH上のMPIプロセス間通信のためのコミュニケータ(mpi_comm_vh),そしてVH-VE間のMPIプロセス間通信のためのコミュニケータ(mpi_comm_world)の合計3つのコミュニケータによりMPI通信を制御する.全体で共通のコミュニケータであるmpi_comm_worldをmpi_comm_split により分割して新しいコミュニケータ(mpi_comm_veおよびmpi_comm_vh)を生成する.
VE向けに用意されているコンパイラコマンド(mpinfort,mpincc,mpinc++)を使用してVE applicationのコンパイルを行う.さらに,-vhオプションを使用することで,VE向けのコンパイラコマンドを使用してx86 applicationのコンパイル(GNUコンパイラ)を行うことも可能である.図 5.3.3‑2にVE application,x86 applicationのコンパイル例を記載する.
# VE application
$ mpinfort -o ve.out ve_applicatin.f90
# x86 application
$ mpinfort -vh -o vh.out vh_application.f90
図 5.3.3‑2 VE application および x86 application のコンパイル例
環境変数の設定により,x86 application向けのコンパイラをGNUコンパイラから変更することができる.図 5.3.3‑3にIntelコンパイラを使用する場合の設定例を記載する.
$ export NMPI_CC_H=icc
$ export NMPI_CXX_H=icpc
$ export NMPI_FC_H=ifort
$ mpincc -vh vh_allication.c
$ mpinc++ -vh vh_application.cpp
$ mpinfort -vh vh_application.f90
図 5.3.3‑3 x86 application のコンパイラの変更方法
図 5.3.3‑4にハイブリッド実行を行う場合の実行コマンドイメージを記載する.
$ mpirun -ve 0-1 -np 4 ./ve.out : \\
-vh -np 2 ./vh.out
図 5.3.3‑4 ハイブリッド実行のコマンドイメージ
VE applicationではVE0およびVE1それぞれで2MPIプロセスが起動され,x86 applicationでは2MPIプロセスが起動される.図 5.3.3‑5に,MPIプロセスの配置イメージを記載する.
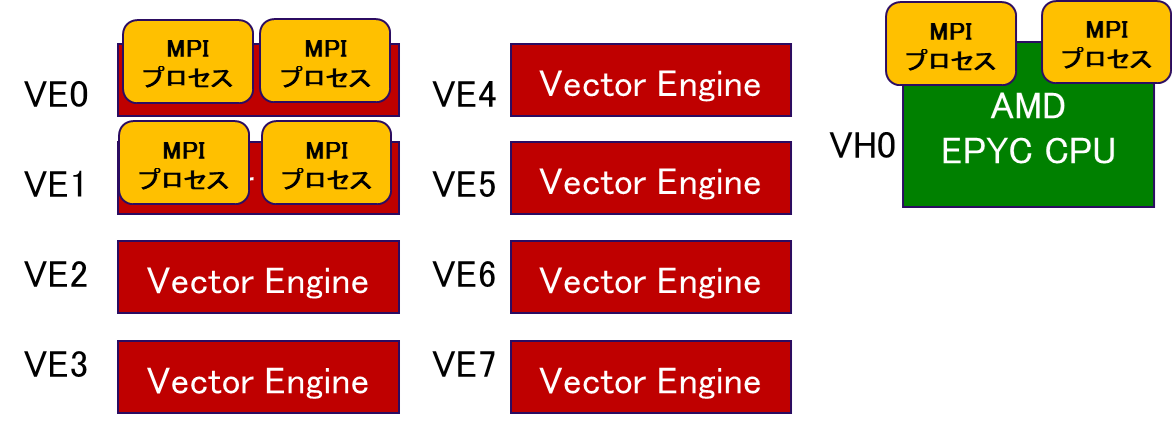
図 5.3.3‑5 MPIプロセスの配置イメージ¶
※3 https://sxauroratsubasa.sakura.ne.jp/documents/mpi/pdfs/g2am01-NEC_MPI_User_Guide_ja.pdf
5.4. 性能解析ツール¶
AOBA-Aでは,これまでのSXシリーズと同様に様々な性能解析ツールが利用可能である.性能解析ツールを用いた性能分析により,プログラムのベクトル演算率や平均ベクトル長といった性能指標を確認することで,効率的にプログラムのボトルネックとなっている箇所を特定することができる.ここでは,性能解析ツールとして診断メッセージリスト(Diagnostic Message List),編集リスト(Format List),PROGINF,FTRACEについて記載する.
5.4.1. 診断メッセージリスト¶
コンパイル時に -report-diagnostics,または,-report-allを指定することで「ソースファイル名.L」というファイルがカレントディレクトリに作成され,プログラムのベクトル化,最適化,並列化などの状況が診断メッセージとして出力される.図 5.4.1‑1に診断メッセージリストの出力例を記載する.
LINE DIAGNOSTIC MESSAGE
11: vec( 103): Unvectorized loop.
11: vec( 113): Overhead of loop division is too large.
12: opt(1037): Feedback of array elements.
12: vec( 120): Unvectorizable dependency.:
図 5.4.1‑1 診断メッセージリストの出力例
診断メッセージリストは,プログラムの行番号と,その行に適用したベクトル化・最適化などに関する診断メッセージが出力される.この例では,11行目からのDOループがベクトル化されていないこと,その原因として12行目で計算される配列にベクトル化不可の依存関係があることがわかる.
5.4.2. 編集リスト¶
編集リストは,-report-format,または,-report-allを指定することで「ソースファイル名.L」ファイルに出力される.編集リストには,ループのベクトル化,並列化の情報や,手続きのインライン展開の情報が記載されており,ベクトル化されていないループを容易に特定することができる.図 5.4.2‑1に編集リストの出力例を記載する.オリジナルのソースコードの情報に,それぞれのループのベクトル化や並列化の状況などが視覚的にわかりやすく追記されている.
LINE LOOP STATEMENT
:
10:
11: +------> do i = 1, n
12: | c(i) = a(i) * c(i-1) + b(i) * c(i-2)
13: +------ enddo
14:
:
図 5.4.2‑1 編集リストの出力例
この例では,11行目から13行目のDOループに ”+” 印が記載されている.これは,このDOループがベクトル化されていないことを示している.
以下に,ループのベクトル化,並列化,インライン展開に関する情報の出力例を記載する.
(1) ループ全体がベクトル化された場合¶
ベクトル化されたループに ”V” が表示される.
V------> DO I=1,N
|
V------ END DO
図 5.4.2‑2 ループ全体がベクトル化された場合の編集リスト
(2) ループが部分ベクトル化された場合¶
部分ベクトル化されたループに “S” が表示される.
S------> DO I=1,N
|
S------ END DO
図 5.4.2‑3 ループが部分ベクトル化された場合の編集リスト
(3) ループが条件ベクトル化された場合¶
条件ベクトル化されたループに “C” が表示される.
C------> DO I=1,N
|
C------ END DO
図 5.4.2‑4 ループが条件ベクトル化された場合の編集リスト
(4) ループが並列化された場合¶
並列化されたループに “P” が表示される.
P------> DO I=1,N
|
P------ END DO
図 5.4.2‑5 ループが並列化された場合の編集リスト
(5) ループが並列化,かつ,ベクトル化された場合¶
並列化かつベクトル化されたループに “Y” が表示される.
Y------> DO I=1,N
|
Y------ END DO
図 5.4.2‑6 ループが並列化かつベクトル化された場合の編集リスト
(6) ループがベクトル化されなかった場合¶
ベクトル化されなかったループには “+” が表示される.
+------> DO I=1,N
|
+------ END DO
図 5.4.2‑7 ループがベクトル化されなかった場合の編集リスト
(7) 配列式など,1行にループ全体が含まれる場合¶
ループの構造は “=” で表示される.この例では配列式がベクトル化されていることを示す.
V ======> A = A + B
図 5.4.2‑8 配列式など,1行にループ全体が含まれる場合の編集リスト
(8) ループが一重化された場合¶
一重化されたループの外側ループに “W”,内側ループに “*” が表示される.
W------> DO I=1,N
|*-----> DO J=1,M
||
|*----- END DO
W------ END DO
図 5.4.2‑9 ループが一重化された場合の編集リスト
(9) ループが入れ換えられ,ベクトル化された場合¶
入れ換えた結果ベクトル化されるループに “X” が表示される.
X------> DO I=1,N
|*-----> DO J=1,M
||
|*----- END DO
X------ END DO
図 5.4.2‑10 ループが入れ換えられ,ベクトル化された場合の編集リスト
(10) 外側ループがループアンロールされ,内側ループがベクトル化された場合¶
アンロールされるループに “U” が表示され,ベクトル化されるループに “V” が表示される.
U------> DO I=1,N
|V-----> DO J=1
||
|V----- END DO
U------ END DO
図5.4.2‑11 外側ループがループアンロールされ,内側ループがベクトル化された場合の編集リスト
(11) ループが融合された場合¶
融合したループの範囲について, 記号が表示される.
V------> DO I=1,N
|
| END DO
| DO I=1,N
|
V------ END DO
図 5.4.2‑12 ループが融合された場合の編集リスト
(12) ループが展開された場合¶
展開されるループに “*” が表示される.
*------> DO I=1,4
|
*------ END DO
図 5.4.2‑13 ループが展開された場合の編集リスト
また,ループ処理ではなく,その行の処理がどのように最適化されたかは,その行に付加された文字により確認できる.
“I” 関数呼び出しがインライン展開された
“M” この行を含む多重ループがベクトル行列積ライブラリ呼び出しに置き換えられた
“F” 式に対してベクトル積和命令が生成された
“R” 配列にretain指示行が適用された
“G” ベクトル収集命令が生成された
“C” ベクトル拡散命令が生成された
“V” 配列にvreg指示行※1,または,pvreg指示行※1が適用された
※1 https://sxauroratsubasa.sakura.ne.jp/documents/sdk/pdfs/g2af02-FortranUsersGuide-033.pdf
5.4.2. PROGINF¶
PROGINFは,プログラム全体の性能解析情報を出力する機能であり,プログラム終了時に,標準エラー出力ファイルに出力される.PROGINFを確認することで,プログラム全体のベクトル演算率,平均ベクトル長といった性能指標を確認することができる.図 5.4.3‑1にPROGINFの出力例を記載する.
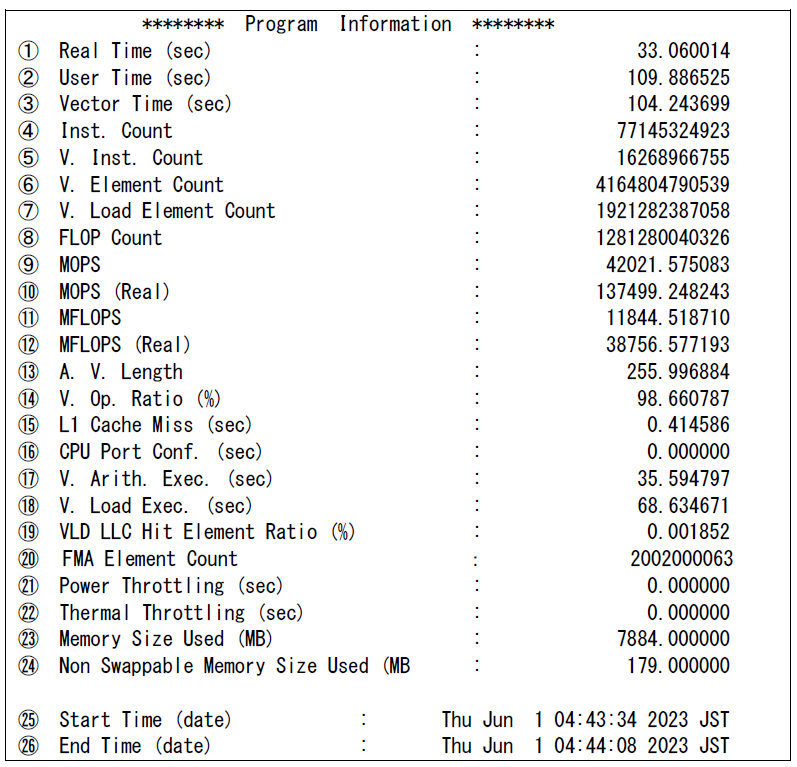
図 5.4.3‑1 PROGINFの出力例¶
表示される各項目の意味は以下の通り.
① Real Time 経過時間(秒)
② User Time ユーザ時間(秒)
③ Vector Time ベクトル命令実行時間(秒)
④ Inst. Count 全命令実行数
⑤ V. Inst. Count ベクトル命令実行数
⑥ V. Element Count ベクトル命令実行要素数
⑦ V. Load Element Count ベクトル命令ロード要素数
⑧ FLOP Count 浮動小数点データ実行要素数
⑨ MOPS ユーザ時間1秒あたりに実行された演算数(100万単位)
⑩ MOPS (Real) 経過時間1秒あたりに実行された演算数(100万単位)
⑪ MFLOPS ユーザ時間1秒あたりに処理された浮動小数点データ実行要素数(100万単位)
⑫ MFLOPS (Real) 経過時間1秒あたりに処理された浮動小数点データ実行要素数(100万単位)
⑬ A. V. Length 平均ベクトル長
⑭ V. OP. RATIO ベクトル演算率(%)
⑮ L1 Cache Miss L1キャッシュミス時間※1
⑯ CPU Port Conf CPUポート競合時間※1
⑰ V. Arith Exec ベクトル演算実行時間※1
⑱ V. Load Exec ベクトルロード実行時間※1
(Vector Time – V.Arith Exec – V.Load Execがベクトルストア実行時間やレジスタ間転送などの転送命令実行時間となる)
⑲ VLD LLC Hit Element Ratio ベクトルロード命令によりロードされた要素のうち,LLCからロードされた要素の比率※1
⑳ FMA Element Count FMA命令実行要素数※1
㉑ Power Throttling 電力要因によるHW停止時間※1
㉒ Thermal Throttling 温度要因によるHW停止時間※1
㉓ Memory Size メモリの最大使用量(メガバイト)
㉔ Non Swappable Memory Size Used Partial Proces Swapping機能※2でスワップアウトできないメモリの最大使用量
㉕ Start Time (date) プログラムの実行開始時間
㉖ End Time (date) プログラムの実行終了時間
上記のうち※1の項目は,VE_PROGINF環境変数の設定にDETAILを指定したときに出力される.
また,VE_PERF_MODE環境変数の設定にVECTOR-MEMを指定することで,主にメモリアクセスに関する情報を出力させることができる.図 5.4.3‑2にVECTOR-MEMを指定した場合の出力例を記載する.なお,VE_PERF_MODEの指定が変わると,メモリアクセス数の計算方法が変わるため,1回の情報採取ではどちらか一方の性能情報しか表示させることしかできない.
※2 https://sxauroratsubasa.sakura.ne.jp/documents/nqsv/pdfs/g2ad06-NQSVUG-JobManipulator.pdf

図 5.4.3‑2 PROGINFの出力例(VECTOR-MEM指定時)¶
表示される各項目の意味は以下の通り.
① L1 I-Cache Miss L1命令キャッシュミス時間(秒)
② L1 O-Cache Miss L1 オペランドキャッシュミス時間(秒)
③ L2 Cache Miss L2キャッシュミス時間(秒)
④ Required B/F ロード命令とストア命令に指定されたバイト数から算出したB/F
⑤ Required Store B/F ストア命令に指定されたバイト数から算出したB/F
⑥ Required Load B/F ロード命令に指定されたバイト数から算出したB/F
⑦ Actual V. Load B/F ベクトルロード命令により実際に発生したメモリアクセスのバイト数から算出したB/F
5.4.4. FTRACE¶
PROGINFを使用することで,プログラム全体の性能情報を採取することが可能であるが,プログラムの中で性能のボトルネックとなる箇所を特定するためには,より細かい単位(手続きごと)での性能情報の採取が必要になる.FTRACEを使用することで,手続き(サブルーチン)ごとや,ユーザの指定した任意の区間の性能情報(実行時間,ベクトル演算率,平均ベクトル長など)を採取することができる.プログラムの実行に時間がかかっている部分をチューニングすることで,効率よくプログラムを高速化することができる.FTRACEを使用するためには,コンパイル時に「-ftrace」オプションを指定する.プログラム実行後,実行ディレクトリに ftrace.out というファイルが作成される.このftrace.outが存在するディレクトリでftraceコマンドを実行することで手続きごとの性能情報が出力される.図 5.4.4‑1にFTRACEによる性能解析情報の例を記載する.
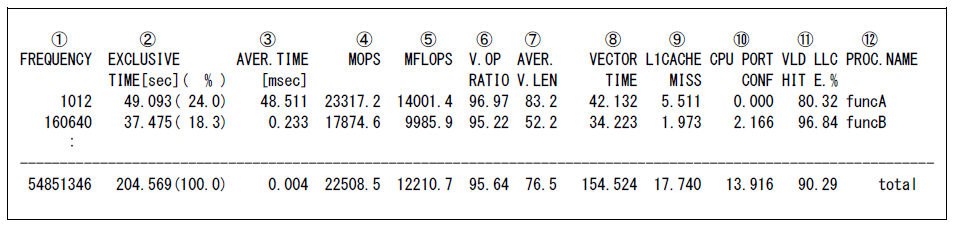
図 5.4.4‑1 FTRACEの出力例¶
表示される各項目の意味は以下の通り.
① FREQUENCY 手続きの呼び出し回数
② EXCLUSIVE TIME 手続きの実行に要したEXCLUSIVEなCPU時間(秒)と,全手続きのCPU時間に関する比率(%)
③ AVER.TIME 手続きの1回の実行に要したEXCLUSIVEなCPU時間の平均(ミリ秒)
④ MOPS “EXCLUSIVE TIME” 1秒あたりに実行された演算数(100万単位)
⑤ MFLOPS “EXCLUSIVE TIME” 1秒あたりに処理された浮動小数点データ実行要素数(100万単位)
⑥ V.OP RATIO ベクトル演算率(%)
⑦ AVER V.LEN 平均ベクトル長
⑧ VECTOR TIME ベクトル命令実行時間(秒)
⑨ L1CACHE MISS L1キャッシュミス時間(秒)
⑩ CPU PORT CONF CPUポート競合時間(秒)
⑪ VLD LLC HIT E. ベクトルロード命令によりロードされた要素のうち,LLCからロードされた要素の比率
⑫ PROC.NAME 手続き名
PROGINFと同様に,FTRACEでもVE_PERF_MODE環境変数の設定にVECTOR-MEMを指定することで,主にメモリアクセスに関する情報を出力させることができる.図 5.4.4‑2にVECTOR-MEMを指定した場合の出力例を記載する.
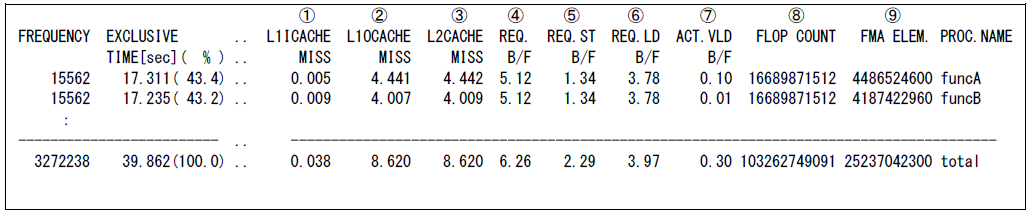
図 5.4.4‑2 FTRACEの出力例(VECTOR-MEM指定時)¶
表示される各項目の意味は以下の通り.
① L1ICACHE MISS L1命令キャッシュミス時間(秒)
② L1OCACHE MISS L1オペランドキャッシュミス時間(秒)
③ L2CACHE MISS L2キャッシュミス時間(秒)
④ REQ. B/F ロード命令とストア命令に指定されたバイト数から算出したB/F
⑤ REQ. ST B/F ストア命令に指定されたバイト数から算出したB/F
⑥ REQ. LD B/F ロード命令に指定されたバイト数から算出したB/F
⑦ ACT. VLD B/F ベクトルロード命令により実際に発生したメモリアクセスのバイト数から算出したB/F
⑧ FLOP COUNT 浮動小数点データ実行要素数
⑨ FMA ELEM. FMA命令実行要素数
MPIプログラムについてもFTRACE情報を採取することができる.MPIプログラムの場合には,上記の情報に加えて,MPI通信情報が含まれる.図 5.4.4‑3にMPI通信情報の出力例を示す.
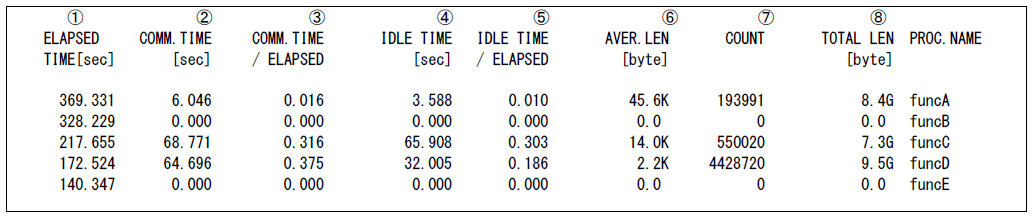
図 5.4.4‑3 MPIプログラムにおけるFTRACEの出力例¶
表示される各項目の意味は以下の通り.
① ELAPSED TIME 経過時間(秒)
② COMM.TIME MPI手続きの実行に費やした経過時間(秒)
③ COMM.TIME / ELAPSED各プロセスにおいて,MPI手続きの実行に費やした時間経過時間が,経過時間全体に占める割合
④ IDLE TIME メッセージ待ちに費やした経過時間
- ⑤ IDLE TIME / ELAPSED
各プロセスにおいて,メッセージ待ちに費やした経過時間が,経過時間全体に占める割合
⑥ AVER.LEN MPI手続きあたりの平均通信量(バイト,単位は1024換算)
⑦ COUNT MPI手続きによる転送回数
⑧ TOTAL LEN MPI手続きによる総通信量(バイト,単位は1024換算)
FTRACEを使用することで詳細な性能情報を採取することが可能になるが,性能情報採取のためのタイマールーチンがプログラム中に埋め込まれるため実行時間が長くなる場合がある.そのため,FTRACEはあくまで性能分析のときにのみ使用し,それ以外のケースでは「-ftrace」オプションは無効にする必要がある.
5.4.5. FILEINF¶
プログラム実行時に,環境変数 VE_FORT_FILEINFにYESもしくはDETAILを指定することで,ファイル入出力情報を出力させることができる.図 5.4.5‑1にVE_FORT_FILEINFにDETAILを指定した場合の出力例を示す.

図 5.4.5‑1 FILEINFの出力例(DETAIL指定時)¶
表示される各項目のうち主なものの意味は以下の通り.
① Unit No. 外部装置識別子
② File Name FILE指定子あるいは事前接続の際に指定した名前
③ Current Directory 現在作業しているディレクトリ名
④ Total Data Size 入出力を行った総転送量を、入出力の合計、入力の合計、出力の合計の順にバイト単位で出力します。
⑤ Max Data Size 入出力の中で最も大きい記録長の値を入力,出力の順にバイト単位で出力
⑥ Min Data Size 入出力の中で最も小さい記録長の値を入力,出力の順にバイト単位で出力
⑦ Ave Data Size 平均記録長を,入出力の合計,入力の合計,出力の合計の順にバイト単位で出力
- ⑧ Transfer Rate
ファイル転送速度を秒あたりのキロバイト(1024バイト)単位で示したもの.転送速度は,Total Data SizeをReal Timeで割った値をキロバイト(1024バイト)単位で示した値で出力
上記以外のパラメータの意味については以下を参照のこと.
https://sxauroratsubasa.sakura.ne.jp/documents/sdk/pdfs/g2af02-FortranUsersGuide-033.pdf