6. 高速化事例¶
スーパーコンピューティング研究部 滝沢寛之 高橋慧智 下村陽一
情報部デジタルサービス支援課 大泉健治 小野敏 山下毅 齋藤敦子 森谷友映
高性能計算技術開発(NEC)共同研究部門 撫佐昭裕 磯部洋子 曽我隆 山口健太
日本電気株式会社 加藤季広
本章では,最適化方法およびその最適化の効果について具体的な事例を用いて説明する.表 6‑1に,本章で説明する最適化事例の一覧を記載する.
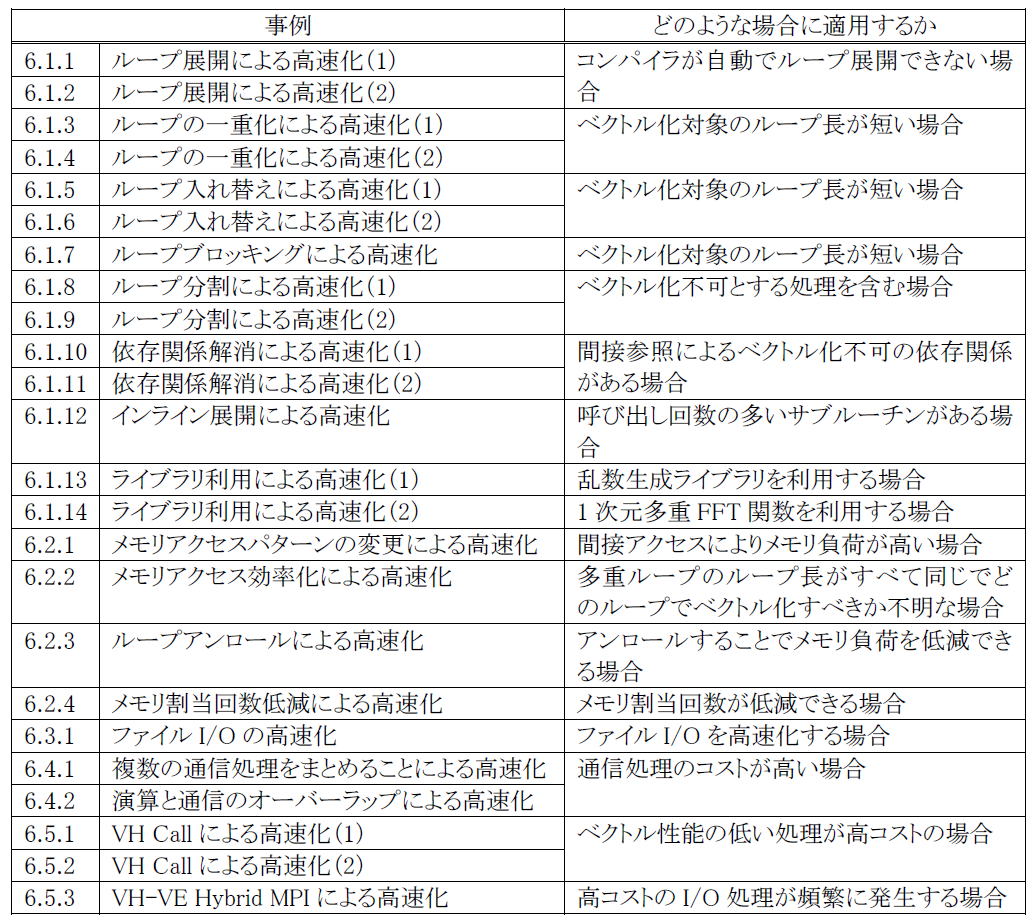
表 6‑1 最適化事例一覧
6.1. ベクトル化推進の事例¶
6.1.1. ループ展開による高速化(1)¶
(1) 最適化方針¶
多重DOループがある場合,コンパイラは原則的に最内ループに対してベクトル化を行う.本事例は,ベクトル化を行った最内ループのベクトル長が短く性能が出ていないため,最内ループを展開して高速化を行った例である.
図 6.1.1‑1に最適化前のコードを示す.四重DOループの最内ループは,コンパイラの自動ベクトル化機能によりベクトル化されている.図 6.1.1‑2に示した最適化前のFTRACE情報では,平均ベクトル長が14.4と低い値になっている.これは,ベクトル化されたインデックス L を持つ最内ループの繰り返し数が13と短いためである.最内ループを展開するUNROLL指示行を挿入し,コンパイラでループを展開して,その外側のループ長の長いDOループをベクトル化することによって実行時間の短縮を図る(注1).

図 6.1.1‑1 ループ展開前のコード¶

図 6.1.1‑2 ループ展開前のFTRACE情報¶
注1)コンパイラによる最適化レベルが2(-O2)以上である場合,最内ループ長がコンパイル時に確定しており,それをコンパイラが検出可能であれば,ループ長が4以下の場合はそのループが自動的に展開される.自動ループ展開の対象とするか否かの閾値m(既定値はm=4)はコンパイラオプション-floop-unroll-complete=mで指定できる.既定値がm=4と比較的小さな値となっているのは,自動ループ展開適用の結果としてコンパイルに要する時間が極端に増加したり,コード行数の増加によってレジスタスピルが発生して性能が低下したりする懸念があるためである.
(2) 最適化内容¶
図 6.1.1‑3に最適化後のコードを示す.最内ループのループ長については,コード上に即値で記述されているので,UNROLL指示行にループ長13を指定して最内ループを展開する.編集リストでは最内ループが展開されたことを示す,*マークが付加され,その外側のDOループにベクトル化されたことを示すVマークが付加されている.

図 6.1.1‑3 ループ展開後のコード¶
(3) 性能分析¶
図 6.1.1‑4に最適化前後の性能値を示す.

図 6.1.1‑4 ループ展開前後のFTRACE情報¶
UNROLL指示行の挿入により,最内ループが展開され,その外側のDOループがベクトル化されたことで,平均ベクトル長が14.4から198.1に増加し,実行時間が270.4秒から21.9秒に短縮されている.
6.1.2. ループ展開による高速化(2)¶
(1) 最適化方針¶
本事例は最内ループの繰り返し範囲が配列もしくは変数で定義され,コンパイル時に繰り返し数を確定することが出来ないため,ループ展開の対象とならないDOループに対し,ユーザがDOループの繰り返し範囲を定数として明記することで,ループ展開の対象とする手法である.
図 6.1.2‑1に最適化前のコードを示す.本コードは三重ループの最内DOループの終値が配列 jn1(k)-1 または変数 jn2 で与えられているが,プログラムの実行中に取り得る値は,jn1(k)-1=2および,jn2=5と定数になることが明確になっている.
このことから,DOループの終値を定数で記述することでコンパイラのループ展開の対象とし,その外側のループ長の大きいDOループでベクトル化することにより実行時間の短縮を図る.
図 6.1.2‑2に示したFTRACE情報から,最適化前はベクトル演算率が42.54% ,平均ベクトル長が4.8と低く,ベクトルプロセッサの性能を十分に発揮できていないことが分かる.
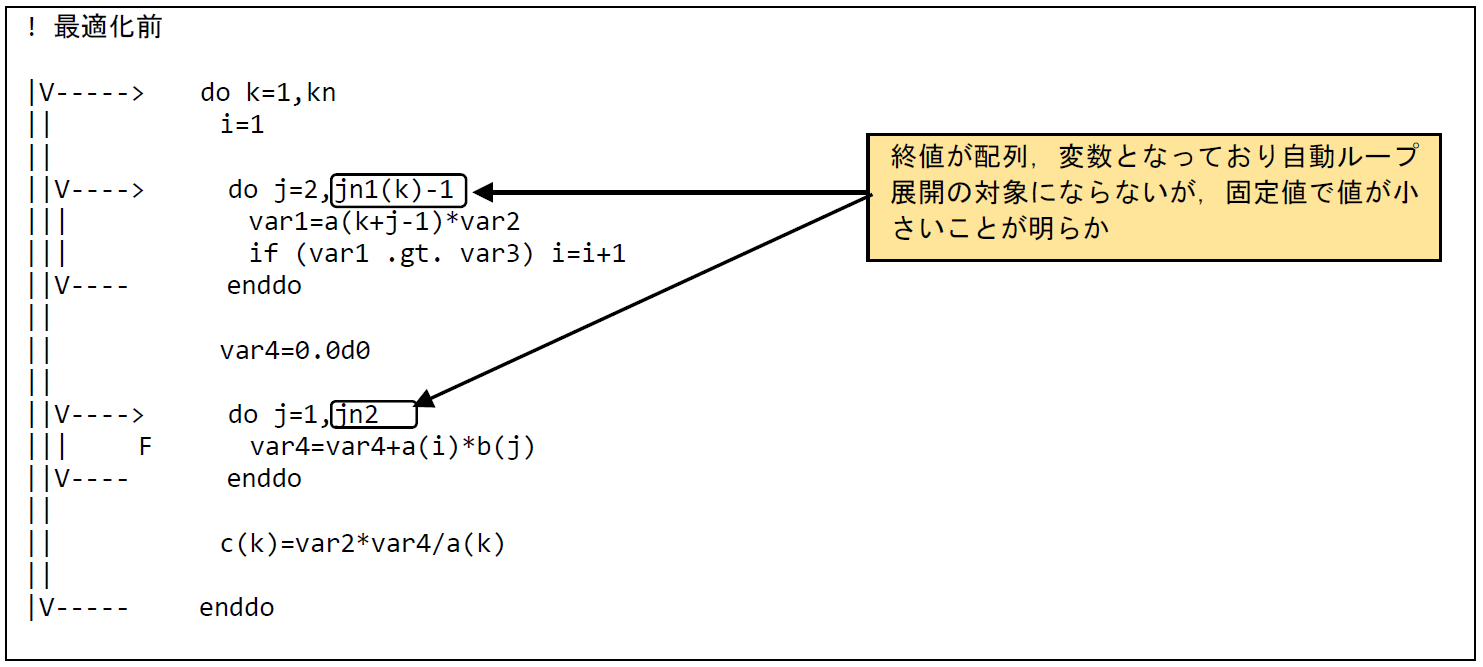
図 6.1.2‑1 ループ展開前のコード¶

図 6.1.2‑2 ループ展開前のFTRACE情報¶
(2) 最適化内容¶
図 6.1.2‑3に最適化後のコードを示す.最内ループの終値を定数で指定することで,コンパイラにより最内DOループのループ展開が自動で行われ,その外側のDOループがベクトル化されたことが確認できる.
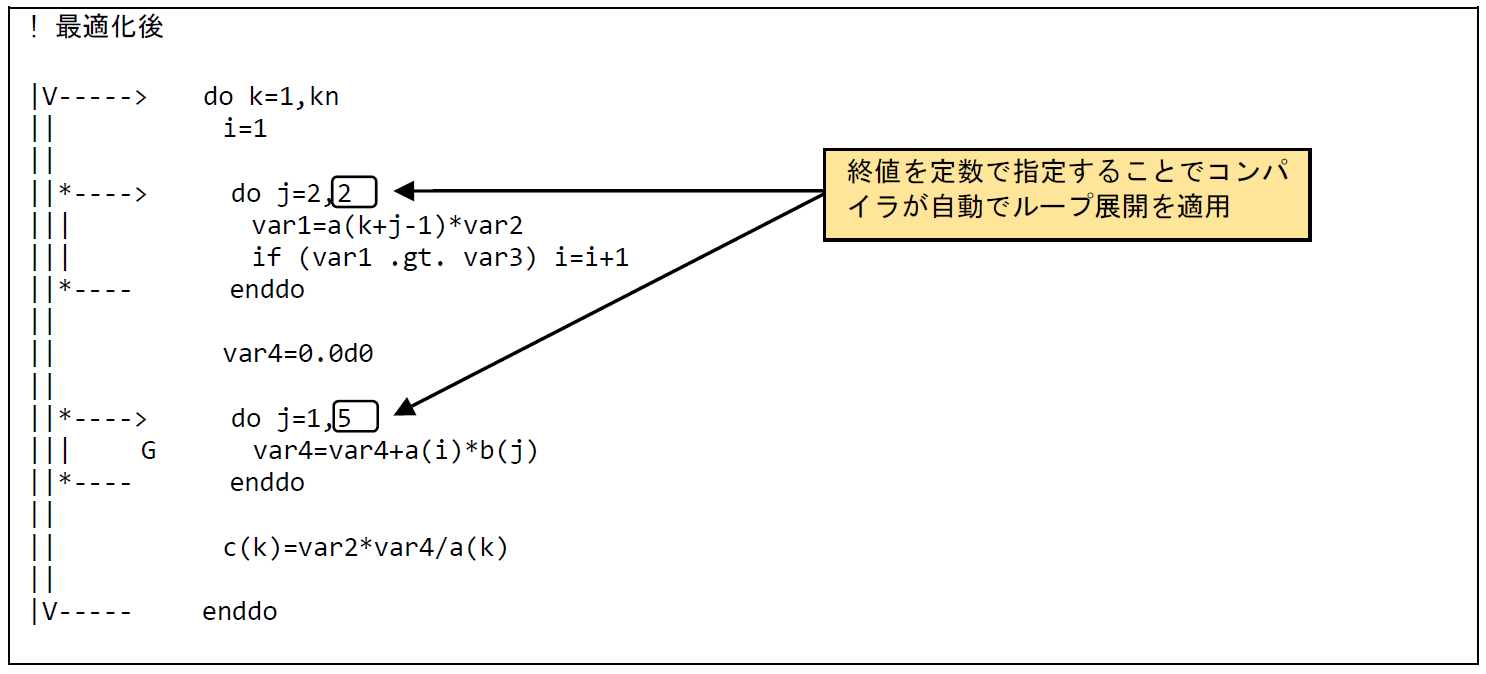
図 6.1.2‑3 ループ展開後のコード¶
(3) 性能分析¶
図 6.1.2‑4に,最適化前後の性能値を示す.

図 6.1.2‑4 ループ展開前後のFTRACE情報¶
最内ループが展開され,その外側のDOループがベクトル化されたことにより,ベクトル演算率が42.54% から99.41 %に,平均ベクトル長が4.8から252.6まで増加し,実行時間が3.3秒から0.002秒に短縮されている.
6.1.3. ループの一重化による高速化(1)¶
(1) 最適化方針¶
多重DOループがある場合,コンパイラは原則的に最内ループに対してベクトル化を行う.本事例は,ベクトル化の対象となった最内ループのベクトル長が十分でないため,多重ループを単一のループとすることでベクトル長を拡大し,高速化を行った事例である.
図 6.1.3‑1に最適化前のコードを示す.allocatable属性が付加されており,実行時に動的にallocateされる多次元配列は,演算範囲が連続であってもコンパイラがそれを判断できないため多重ループが一重化されない.この事例では,ベクトル化されるループのループ長は,配列の1次元目のサイズ(in)で定義され,その大きさは441である.そこで,配列式を多重ループに書き下し,メモリ上で連続する領域を単一のループで走査することによりベクトル長を拡大して実行時間の短縮を図る.
図 6.1.3‑2に示す最適化前のFTRACE情報では,ベクトル演算率は97% 以上と比較的高い値となっており,平均ベクトル長も216.5と良好な値となっているが,平均ベクトル長の最大値256に近づけることができればさらなる性能向上が期待できる.

図 6.1.3‑1 ループ一重化前のコード¶

図 6.1.3‑2 ループ一重化前のFTRACE情報¶
(2) 最適化内容¶
図 6.1.3‑3に最適化後のコードを示す.配列式を多重ループに書き下し,メモリ上で連続する領域を単一のループで走査することによりループの一重化を行う. 最内ループにVマークが付加され,二重ループが一重化されたことが確認できる.

図 6.1.3‑3 ループ一重化後のコード¶
(3) 性能分析¶
図 6.1.3‑4に最適化前後の性能値を示す.

図 6.1.3‑4 ループ一重化前後のFTRACE情報¶
ループが一重化されたことで,平均ベクトル長が216.5から255.9に増加している.元々ベクトル長は比較的大きかったため,最適化適用による実行時間の短縮は4% 程度であった.
6.1.4. ループの一重化による高速化(2)¶
(1) 最適化方針¶
本事例はC言語プログラムにおけるループ一重化の事例である.図 6.1.4‑1に最適化前のソースコードを示す.本事例は幾何的マルチグリッド法を用いた標準ベンチマークであるHPGMG-FV (https://hpgmg.org/) から抜粋したものであり,実行時間の多くを占めるGauss-Seidel Red-Black法の一部である. 本コードは三重ループによって構成され,コンパイラは最内のインデックスiのループをベクトル化している.しかし,問題サイズによってはループのループ長が短く,平均ベクトル長が不足する.そこで,インデックスi のループとjのループを一重化し,平均ベクトル長の拡大を試みる.
図 6.1.4‑2に最適化前のFTRACE情報を示す.最適化前は平均ベクトル長が18.1と短いことがわかる.

図 6.1.4‑1ループ一重化前のソースコード¶

図 6.1.4‑2 ループ一重化前のFTRACE情報¶
(2) 最適化内容¶
図 6.1.4‑3に最適化後のソースコードを示す.本コードでは,#pragma _NEC collapse指示行をループに適用してもコンパイラが自動的に一重化を実施しなかったため,手動で一重化を実施し,インデックスijのループを作成する.編集リストより,コンパイラがインデックスijのループをベクトル化したことがわかる.

図 6.1.4‑3ループ一重化後のソースコード¶
(3) 性能分析¶
図 6.1.4‑4に最適化前後のFTRACE情報を示す.

図 6.1.4‑4 ループ一重化後のFTRACE情報¶
平均ベクトル長が18.1から147.1に拡大しており,ループ一重化によってループ長が大幅に拡大している.また,実行時間も419.4秒から280.4秒に短縮されている.
6.1.5. ループ入れ替えによる高速化(1)¶
(1) 最適化方針¶
コンパイラの自動ベクトル化機能により最内ループがベクトル化された場合でも,そのループ長が256に満たない場合にはベクトル演算器の性能が十分に発揮されない場合がある.本事例は多重ループのループ順を入れ替えることで平均ベクトル長を増加させ,演算時間を短縮する手法である.
図 6.1.5‑1に最適化前のコードを示す.本コードはDOループの終値であるinとjnはそれぞれ32および5,840であり,最内側のループはベクトル化されているがループ長は256よりも小さい.一方その外側のループ長は5,840で,十分に長いループ長となっているので,一時配列を導入して演算結果をDOループのインデックスに依存しない形で保存することで,最内ループと外側ループのループ入れ換えにより実行時間の短縮を図る.
図 6.1.5‑2に示したFTRACE情報から,最適化前は平均ベクトル長が56.8と低く,最内ループがベクトル化されている場合でもベクトルプロセッサの性能を十分に発揮できていないことが分かる.

図 6.1.5‑1 ループ入れ替え前のコード¶

図 6.1.5‑2 ループ入れ替え前のFTRACE情報¶
(2) 最適化内容¶
図 6.1.5‑3に最適化後のコードを示す.ループ入れ替え前のコードでは,変数var1は内側のiのループ内で足しこみ演算が行われ,外側のjのループがまわるごとに更新される.つまり,jごとにiのループの足しこみ演算の結果を持っておく必要がある.そこで,最内DOループとその外側のDOループの順序を入れ替えるために,一時配列 work1(jn) を導入した.この配列に1からjnまでの足し込み演算の結果を格納することで,jのループを最内側としてベクトル化が可能となる.最内側になったjのループにVマークが付加されており,ベクトル化されたことがわかる.

図 6.1.5‑3 ループ入れ替え後のコード¶
(3) 性能分析¶
図 6.1.5‑4に,最適化前後の性能値を示す.

図 6.1.5‑4 ループ入れ換え前後のFTRACE情報¶
最内ループとその外側のループを入れ替えたことにより,ベクトル演算率が97.14% から99.41 %に,平均ベクトル長が56.8から254.1まで増加し,実行時間が11.8秒から0.5秒に短縮されている.
6.1.6. ループ入れ替えによる高速化(2)¶
(1) 最適化方針¶
本事例は,2次元配列による配列式がベクトル化されるさいに,要素数の少ない次元にアクセスするループがベクトル化の対象となってされてしまう事例である.
図 6.1.6‑1に最適化前のコードを記載する.2次元配列 aおよびbの計算が配列式として記述されている.配列の1次元目,2次元目の要素数はそれぞれin,jn となっており,in = 4,jn = 5,067,629である.この配列式はコンパイラにより二重ループに展開されるが,最内ループは配列の1次元目にアクセスするように展開されるため,ベクトル化対象のループのループ長が4になってしまう.そこで,ループ長が非常に大きい2次元目がベクトル化の対象となるように最適化を行い平均ベクトル長を拡大する.図 6.1.6‑2に最適化前のFTRACE情報を記載する.平均ベクトル長が4となっており,要素数の小さい1次元目でベクトル化されていることがわかる.

図 6.1.6‑1 ループ入れ替え前のコード¶

図 6.1.6‑2 ループ入れ替え前のFTRACE情報¶
(2) 最適化内容¶
要素数が大きい2次元目でベクトル化を行うためには,いくつか方法が考えられる.一つ目は,配列の次元を入れ替え,要素数が大きい次元を1次元目に変更する方法である.配列の次元を入れ替えたコード例を図 6.1.6‑3に記載する.演算部の配列式の記載は変わっていないが,配列をallocateするさいに,1次元の要素数がjn,2次元目の要素数が in になるようにしている.この配列の次元入れ替えにより,ベクトル化対象ループのループ長が拡大する.二つ目の方法は,配列式をループ構造に書き換え,要素数の小さい次元にアクセスするループをループ展開することで,ループ長の長いループでベクトル化する方法である.ループ展開を適用したコード例を図 6.1.6‑4に記載する.配列式を二重ループ構造に書き下すことで,コンパイラはループ長の短い最内側ループを自動的にループ展開し,外側ループでベクトル化を行っている.

図 6.1.6‑3 配列の次元入れ替え後のコード¶
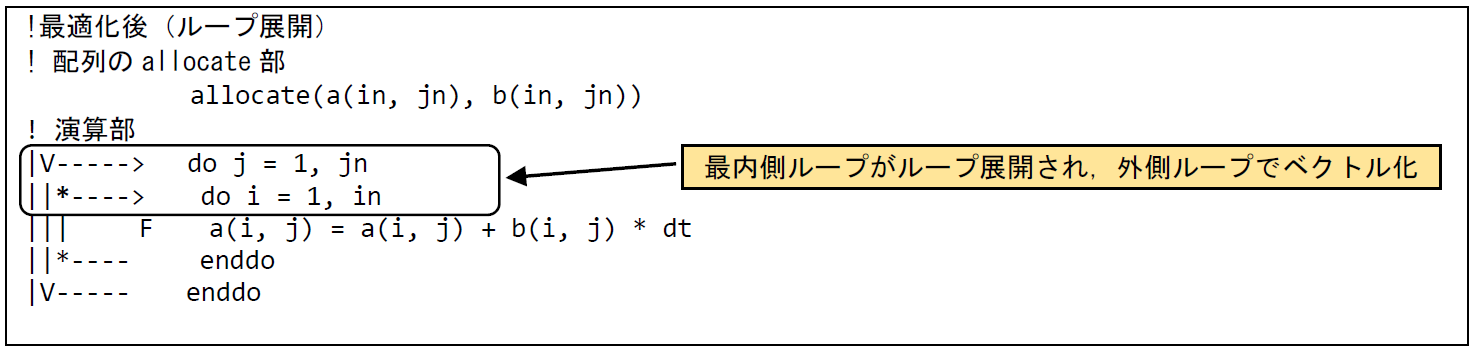
図 6.1.6‑4 ループ展開後のコード¶
(3) 性能分析¶
図 6.1.6‑5に,最適化前後の性能値を示す.

図 6.1.6‑5 最適化前後のFTRACE情報¶
配列の次元入れ替えおよびループ展開により,要素数が大きいループがベクトル化対象になり,平均ベクトル長が4から256に向上している.さらにベクトル演算率も33.7% から99% 以上に改善している.次元入れ替えの場合には,ループ長の大きいループが最内側ループ,ループ長の短いループが外側ループの二重ループの構造として処理されるが,ループ展開の場合には,最内側のループが展開されることで一重ループの構造となりループ呼び出しのオーバヘッドが削減され,最も性能が高くなっていると考えられる.最適化の適用により,実行時間は17.3秒から0.5秒および0.3秒とおよそ40倍以上短縮されている.
6.1.7. ループブロッキングによる高速化¶
(1) 最適化方針¶
本事例は,多重ループ構造において,ベクトル化対象の内側ループのループ長が小さく,外側ループのループ長が大きい場合に,外側ループをブロッキングしてベクトル長を拡大する事例である.
図 6.1.7‑1に最適化前のコードを示す.二重DOループの最内ループは,コンパイラの自動ベクトル化機能によりベクトル化されている.図 6.1.7‑2に示した最適化前のFTRACE情報では,平均ベクトル長が134.0となっている.これは,変数npが6であるため,ベクトル化の対象となっている2つのループのうち,ループインデックスn2のループ長は216であるが,ループインデックスm3のループ長は6であるため,ループインデックスm3のループがボトルネックとなっているためである.一方,最外ループのループ長naは11,430と長いため,最外ループをブロッキングして最内ループに移動することで,ベクトル長の伸長による性能改善を図る.
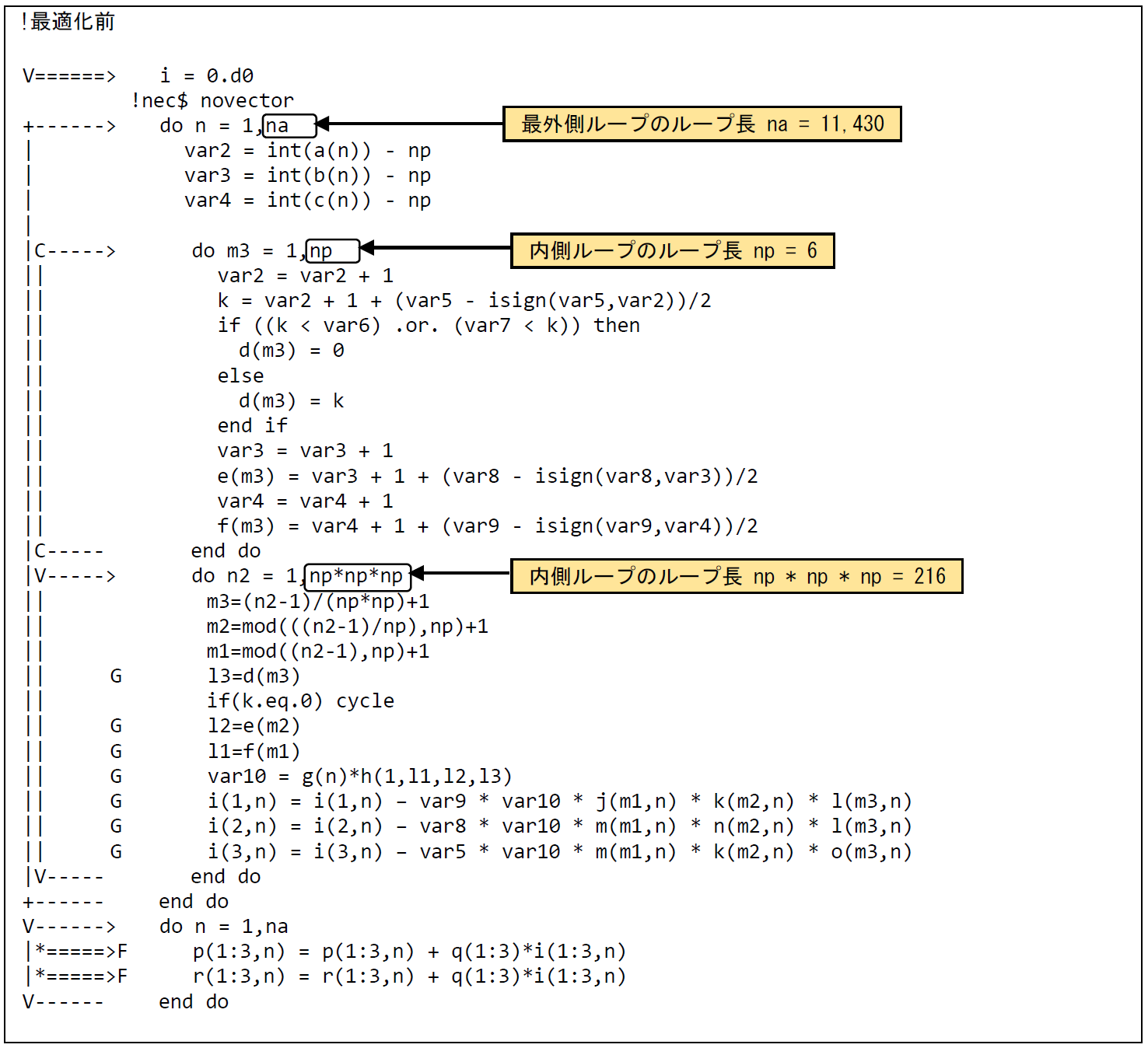
図 6.1.7‑1 ループブロッキング前のコード¶

図 6.1.7‑2 ループブロッキング前のFTRACE情報¶
(2) 最適化内容¶
図 6.1.7‑3に最適化後のコードを示す.最外ループを変数blksz(最大ベクトル長の256)でループブロッキングし,ブロッキングしたループを最内ループに移動することでベクトル化の対象とする. 修正後の編集リストでは,最適化対象の2つのループのどちらもブロッキングにより,より長いベクトル長が得られるループがベクトル化されている.
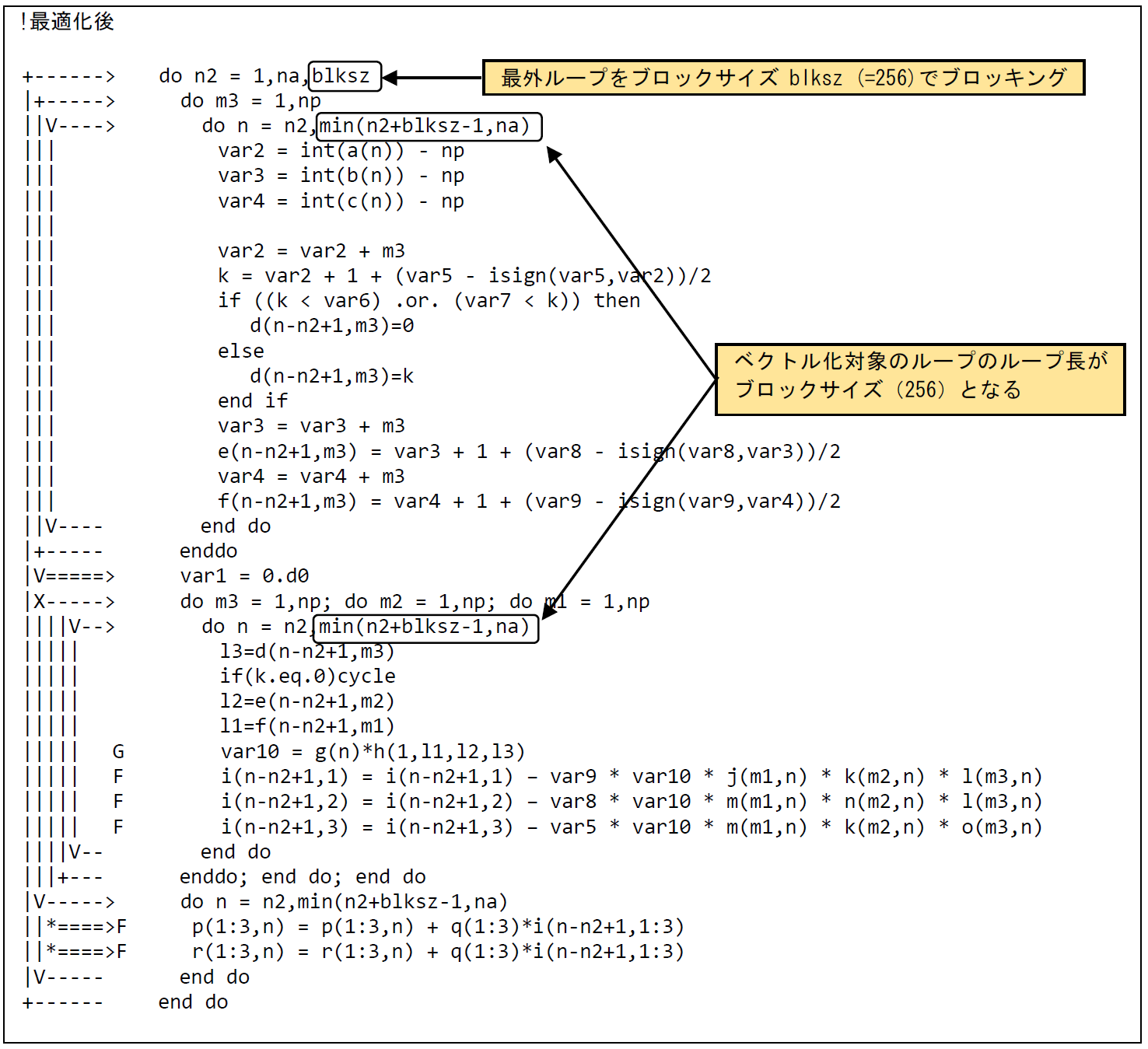
図 6.1.7‑3 ループブロッキング後のコード¶
(3) 性能分析¶
図 6.1.7‑4に,最適化前後の性能値を示す.

図 6.1.7‑4 ループブロッキング前後のFTRACE情報¶
ブロッキングにより分割したループ(最大ループ長がblksz)を最内ループに移動することにより,ベクトルループのループ長が伸長するため,平均ベクトル長が134.0から254.0に増加し,実行時間が3.3秒から0.5秒に短縮されている.
6.1.8. ループ分割による高速化(1)¶
(1) 最適化方針¶
最内ループ内にベクトル化が不可能な処理が含まれる場合,コンパイラはベクトル化が不可能な処理を除くその他処理について,自動ループ分割等による部分ベクトル化を試みる.しかし,ループ分割適用後もコードの意味が保持されるか否かをコンパイラが判断することは一般的に困難であり,自動ループ分割による部分ベクトル化が適用されないケースは多く発生する.本事例は,ベクトル化が不可能な処理を含むループを明示的に分割し,ベクトル化が不可な処理をループ外で行うことでベクトル化を促進し,高速化を行った例である.
図 6.1.8‑1に最適化前のコードを示す.変数var6の値はループ内での総和計算により算出される変数var[1-5]の総和であるためベクトル化不可となっている.しかし,var6の値はこの三重ループ内では参照されないため,var6の計算をこの三重ループ外で行っても,元のコードで期待されているものと同様の結果を得ることができる.
そこで,三重ループをvar6算出処理の前後で分割することでベクトル化を促進して実行時間の短縮を図る.図 6.1.8‑2に示す最適化前のFTRACE情報では,ベクトル演算率が62.8% となっており十分でない.ループ分割によってベクトル化を促進することで性能向上が期待できる.

図 6.1.8‑1 ループ分割前のコード¶

図 6.1.8‑2 ループ分割前のFTRACE情報¶
(2) 最適化内容¶
図 6.1.8‑3に最適化後のコードを示す.太字で強調したDO文およびEND DO文を追加することでループを分割し,ベクトル化の阻害要因となっていたvar6の算出をループ外で行うことでループ変数iのループがベクトル化されている.最内ループであるiループにVマークが付加され,当該ループがベクトル化されたことが確認できる.
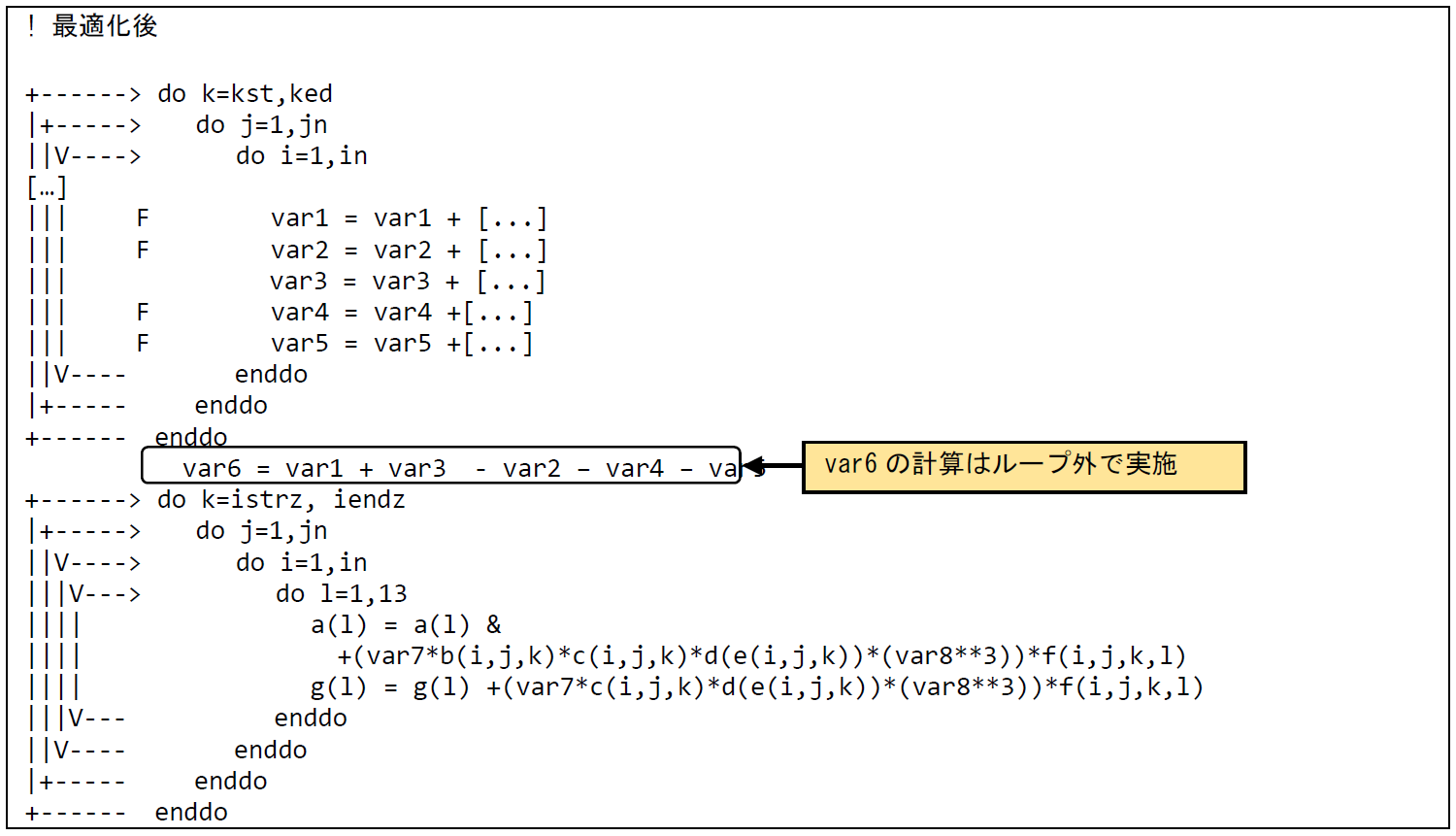
図 6.1.8‑3 ループ分割後のコード¶
(3) 性能分析¶
図 6.1.8‑4に,最適化前後の性能値を示す.

図 6.1.8‑4 ループ分割前後のFTRACE情報¶
ループ分割によるベクトル化促進により,ベクトル演算率が62.8% から95.7% に増加し,実行時間が9,993.5秒から316.3秒に短縮されている.
6.1.9. ループ分割による高速化(2)¶
(1) 最適化方針¶
本事ではベクトル化の対象となるDOループ内にリストベクトル(間接参照)による配列の参照・定義があるためベクトル化が行われていない.そのため,ループを分割してベクトル化可能なループとベクトル化不可のループに分割してループの部分的なベクトル化を促進する例である.
図 6.1.9‑1に最適化前のコードを示す.ループ内で参照・定義している配列g,h,nおよびkのインデックスは,スカラ変数iと配列aの値であるjjとなっている.jjが間接参照(リストベクトル)となるため,iとjjに重なりがあるかコンパイラは判断できずベクトル化の阻害要因となる.そのため,ベクトル化が可能な部分とベクトル化が不可能な部分にループ分割を行う.また,ベクトル化不可のループに対して,LIST_VECTOR指示行を指定することで可能な限りベクトル化を行う.
図 6.1.9‑2のFTRACE情報から,最適化前のベクトル演算率は0.0% でありベクトル化ができていないことが分かる.
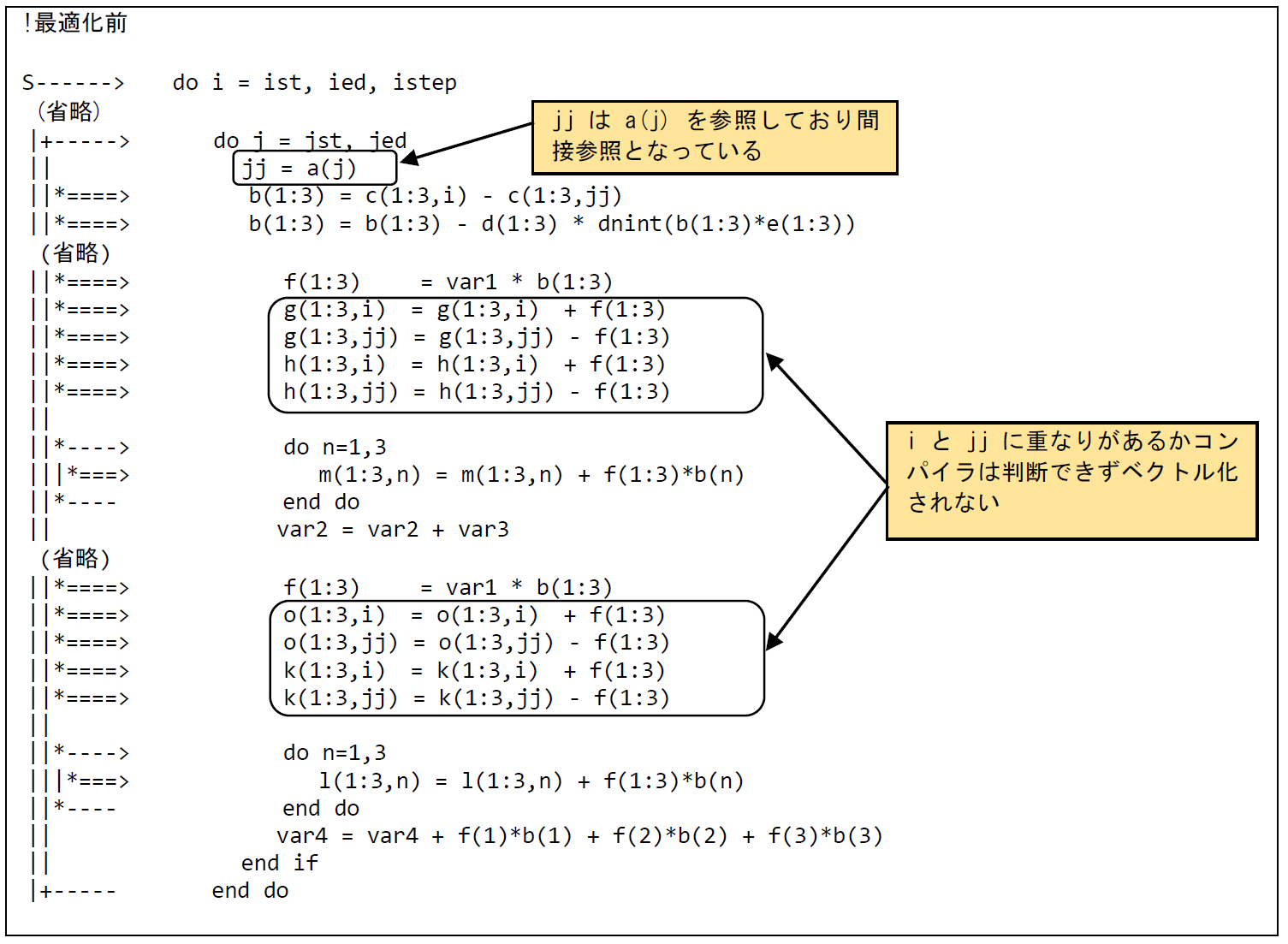
図 6.1.9‑1 ループ分割前のコード¶

図 6.1.9‑2 ループ分割前のFTRACE情報¶
(2) 最適化内容¶
図 6.1.9‑3に最適化後のコードを示す.配列fの値を作業配列work1,変数bの値を作業配列work2に一時保存しループ分割を行う.分割した前半のループは,配列g,h,jおよびkのインデックスはスカラ変数iのみとなるため,コンパイラは総和のマクロを適用してベクトル化を行う.分割した後半のループは,リストベクトルによりベクトル化不可となるため,LIST_VECTOR指示行を挿入し可能な限りのベクトル化を行う.
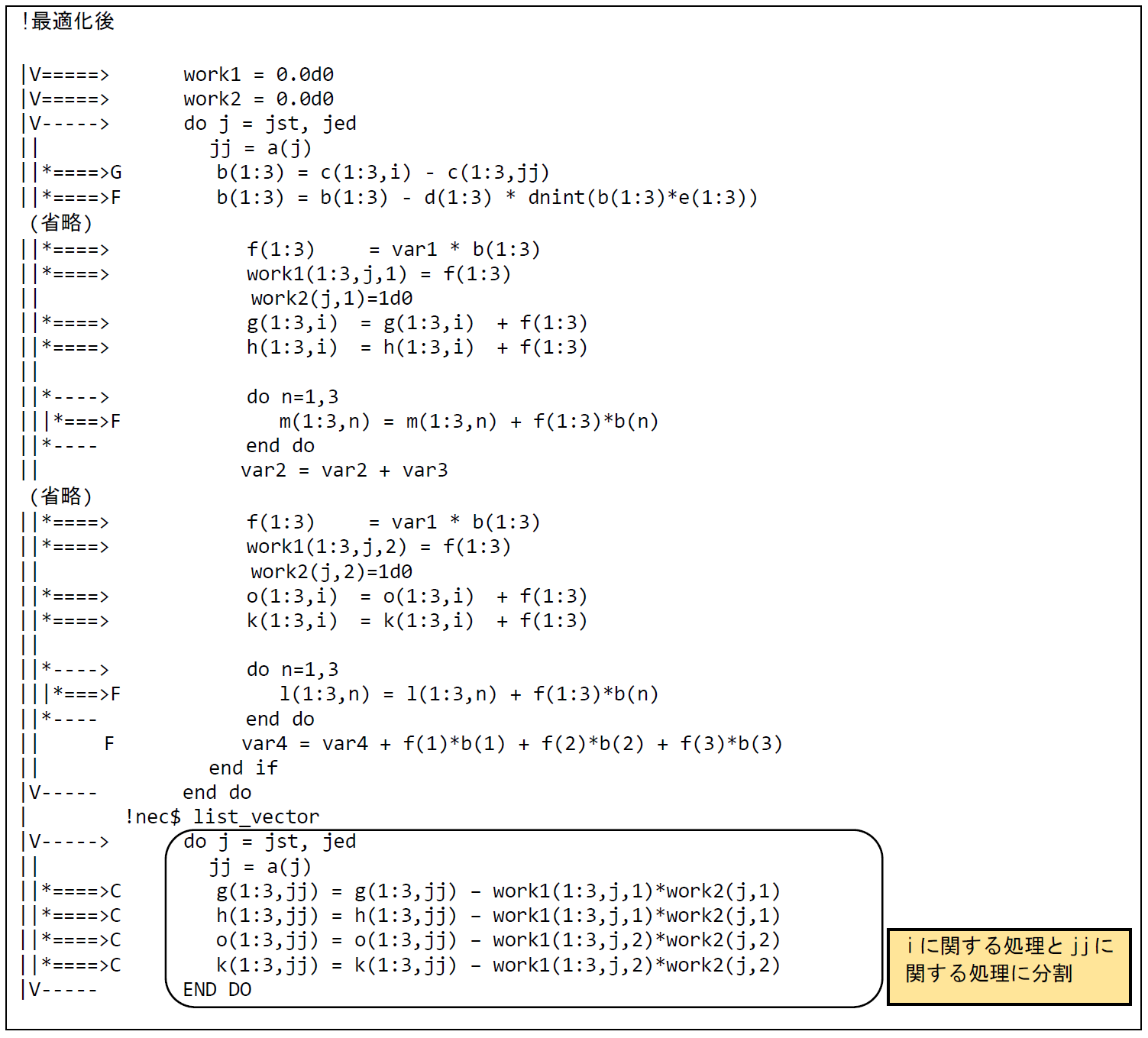
図 6.1.9‑3 ループ分割後のコード¶
(3) 性能分析¶
図 6.1.9‑4に,最適化前後の性能値を示す.

図 6.1.9‑4 ループ分割前後のFTRACE情報¶
ループ分割により,ベクトル化可能部分はベクトル化が行われ,ベクトル化不可部分はLIST_VECTOR指示行により可能な限りのベクトル化が行われた.最適化の効果で,ベクトル演算率は99.4% に向上し,実行時間が61.1秒から7.4秒に短縮されている.
6.1.10. 依存関係解消による高速化(1)¶
(1) 最適化方針¶
コンパイラはプログラムを解析してベクトル命令で実行可能な部分を自動的に検出し,その部分に対してベクトル命令を生成する.対象となるループ,または,配列式にベクトル化可能な部分と不可の部分が混在している場合は,ベクトル化可能な部分のみをベクトル化する.このベクトル化法は部分ベクトル化と呼ばれる.本事例は部分ベクトル化されたDOループに対し指示行 IVDEP を指定することで,ベクトル化不可の依存関係がないと仮定してコンパイラにベクトル化する事を許可する.依存関係があるループをベクトル化すると結果が不正となったり,ベクトル化前後で計算結果が異なったりすることがあるので結果の確認が必要である.
図 6.1.10‑1に最適化前のコードを示す.本コードは最内DOループ内の演算はインデックスが配列の値で与えられる(間接参照)ためコンパイラによる依存関係の有無が判別不可能であり,「部分ベクトル化」を示す ”S” となっている.本コードでは配列a(j) の値に重なりがないこと(単一のベクトル命令で処理される範囲で同一の値が複数回現れないこと)をユーザ側がわかっていたため,このDOループの直前に指示行 IVDEP を指定することで依存関係が無いとし,DOループをベクトル化することにより実行時間の短縮を図る.
図 6.1.10‑2に示したFTRACE情報から,最適化前はベクトル演算率が3.96% と低く,ベクトルプロセッサの性能を十分に発揮できていないことが分かる.
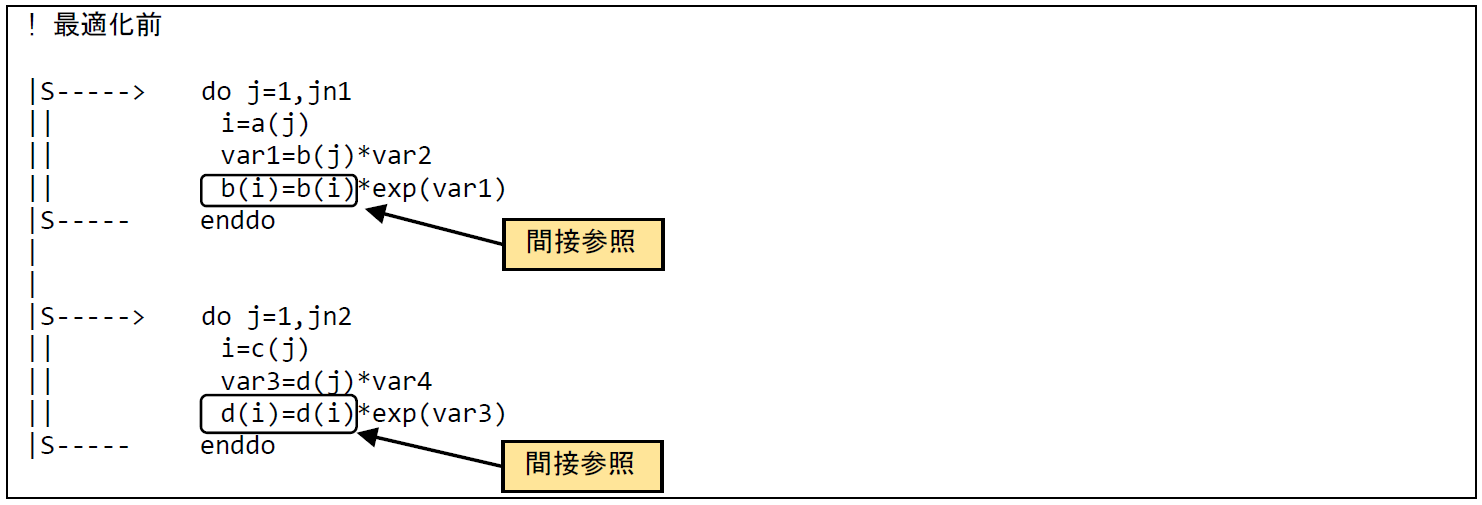
図 6.1.10‑1 指示行挿入前のコード¶

図 6.1.10‑2 指示行挿入前のFTRACE情報¶
(2) 最適化内容¶
図 6.1.10‑3に最適化後のコードを示す.
「部分ベクトル化」となっている2箇所の最内ループの直前に指示行 IVDEP を指定することで依存関係が無いとしたため,コンパイラによりDOループがベクトル化されたことが確認できる.
なお,指数関数の演算文に表記された ”C” は,ベクトル拡散(スキャッター)命令によるベクトル化が行われた事を示す.

図 6.1.10‑3 指示行挿入後のコード¶
(3) 性能分析¶
図 6.1.10‑4に,最適化前後の性能値を示す.

図 6.1.10‑4 指示行挿入前後のFTRACE情報¶
指示行 IVDEP により最内ループをベクトル化したことにより,ベクトル演算率が3.96% から99.35% に増加し,実行時間が5.1秒から0.041秒に短縮されている.
6.1.11. 依存関係解消による高速化(2)¶
(1) 最適化方針¶
コンパイラは原則的に最内ループに対してベクトル化を行うが,当該ループにベクトル化を不可能とする依存関係がないことが保証できない場合にはベクトル化を適用しない.本事例は,ベクトル化を不可能とする依存関係がないことが明確となるようにコードを修正してベクトル化を促進し,高速化を行った例である.
図 6.1.11‑1に最適化前のコードを示す.配列cのi2番目の要素への加算が行われているが,インデックスi2はループ変数i1から算出されており,コンパイラがベクトル化を不可能とする依存関係がないこと(単一のベクトル命令で処理される範囲でi2に重なりがない,つまり,同一の値が複数回現れないこと)を保証できない.そのためベクトル化が行われず,図 6.1.11‑2に示した最適化前のFTRACE情報では,ベクトル演算率が0 % となっている.ベクトル化を不可能とする依存関係がないことが明確となるようにコードを修正し,ベクトル化を促進することによって実行時間の短縮を図る.
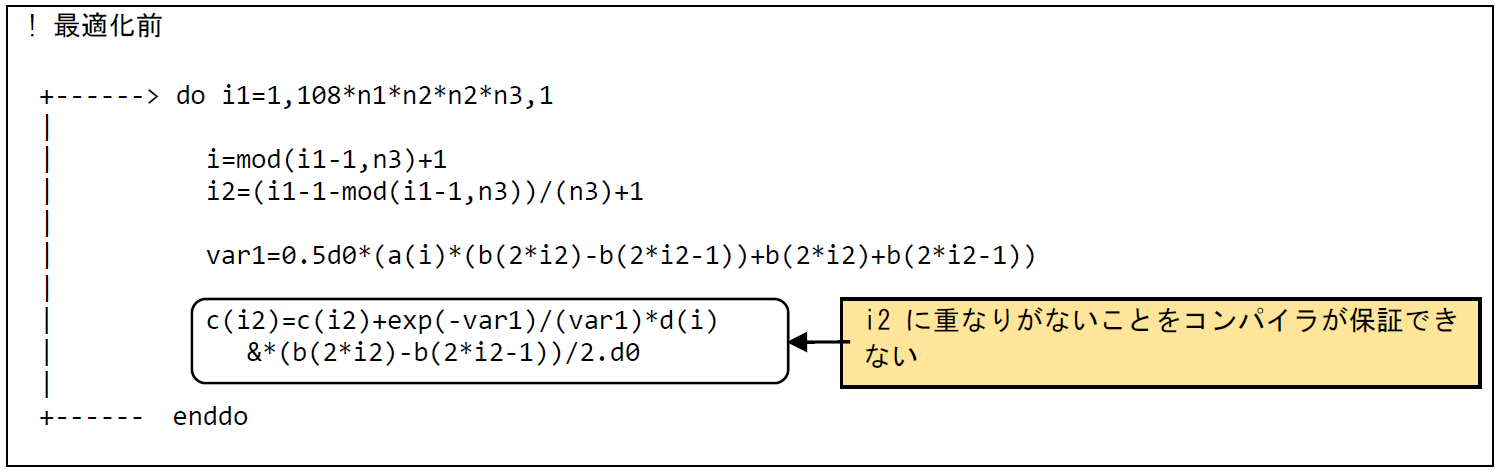
図 6.1.11‑1 依存関係解消前のコード¶

図 6.1.11‑2 依存関係解消前のFTRACE情報¶
(2) 最適化内容¶
図 6.1.11‑3に最適化後のコードを示す.単一のループよる処理を二重ループに書き換え,ループ変数の変換を不要とした.ベクトル化を不可能とする依存関係がないことが明確となりベクトル化が行われた.編集リストでは最内ループがベクトル化されたことを示すVマークが付加されている.
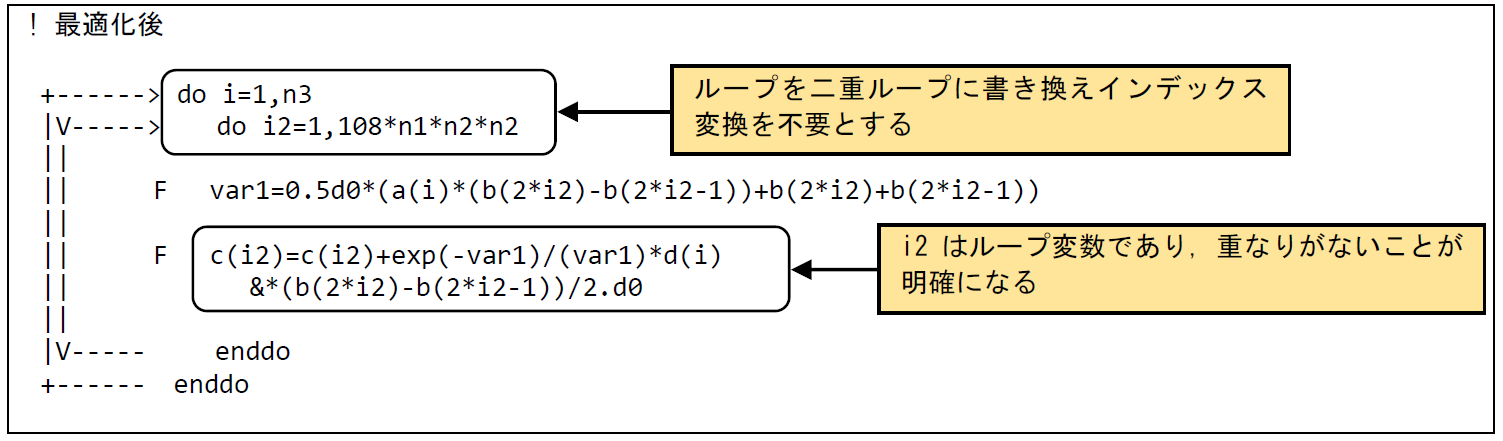
図 6.1.11‑3 依存関係解消後のコード¶
(3) 性能分析¶
図 6.1.11‑4に最適化前後の性能値を示す.

図 6.1.11‑4 依存関係解消前後のFTRACE情報¶
内側のDOループがベクトル化されたことで,ベクトル演算率が0% から99.6% に向上し,実行時間が0.214秒から0.001秒に短縮されている.
6.1.12. インライン展開による高速化¶
(1) 最適化方針¶
一般に手続き(サブルーチンおよび関数)の呼出し回数が多い場合,その呼出し処理のためのオーバヘッドが顕著になり実行時間が長くなることがある.本事例は自動インライ展開を適用するコンパイルオプション -finline-functions のみでは,他ソースコードファイルに記述されたサブルーチンがインライン展開の対象とならない場合に,クロスファイルインライニングを指定するオプション -finline-file でソースファイル名を指定することで呼出回数の多いサブルーチンのインライン展開の対象とする手法である.
なお,インライン展開機能を利用する際に多数の手続きをインライン展開するとプログラムのコードサイズが肥大化し,命令キャッシュからコードが溢れることでプログラム全体の実行性能が低下する事がある.また,インライン展開を大きなソースコードや多数のファイルを対象とする場合,それ以降の処理量が増えコンパイル時間が延びたり,コンパイル時に使用するメモリ量が増加したりするので併せて注意が必要である.
インライン展開を行う場合は図 6.1.12‑1に示したコンパイルオプションを指定する.
また,インライン展開された手続きを確認する場合は,図 6.1.12‑2に示した最適化情報リストを出力するコンパイルオプションを指定する.

図 6.1.12‑1 インライン展開を行うコンパイルオプション¶

図6.1.12‑2 インライン展開モジュールの最適化情報リストを出力するコンパイルオプション¶
図 6.1.12‑3に示したFTRACE情報(演算コスト上位15件)から,-finline-functions オプションのみを指定してインライン展開を行った場合は,○で示した呼出回数の多いサブルーチン4つは,インライン展開の対象外であったことが分かる.
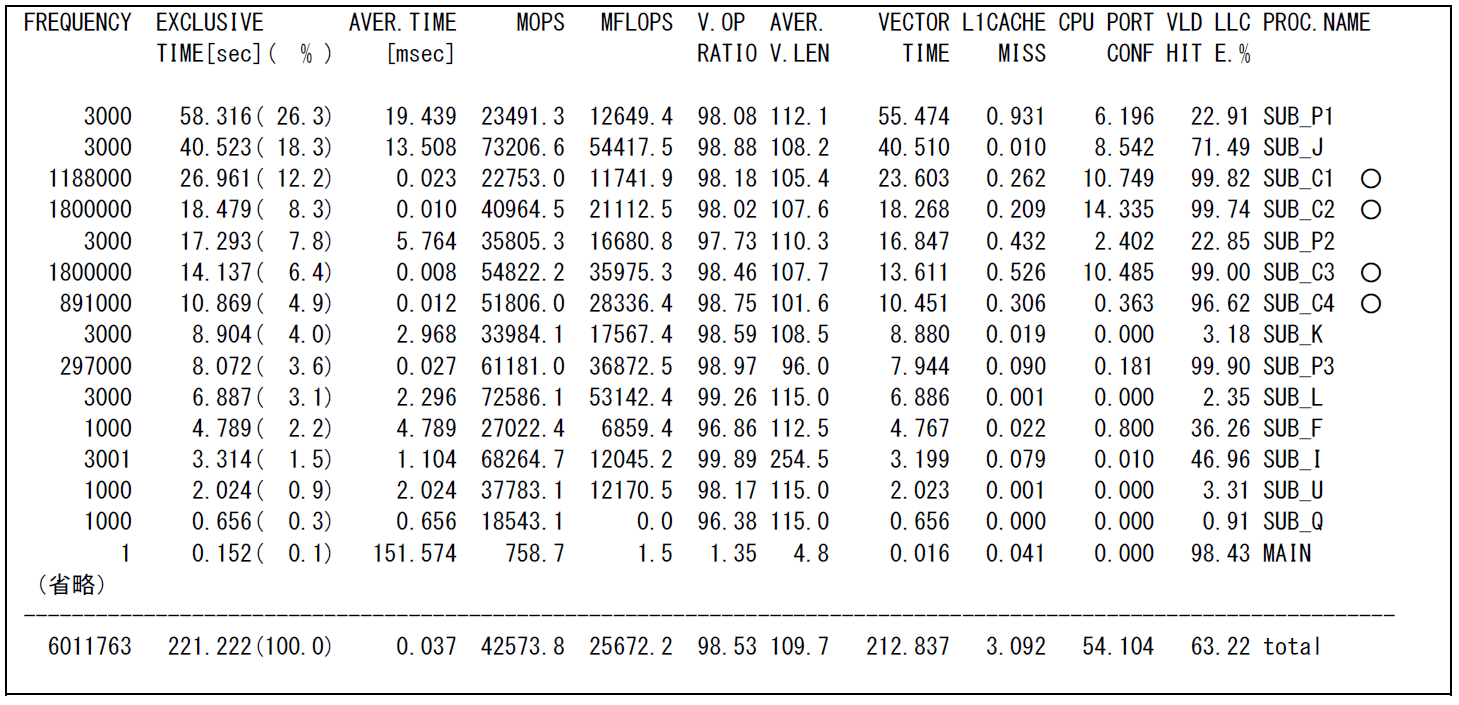
図 6.1.12‑3 -finline-functions オプションのみ指定した場合のFTRACE情報¶
(2) 最適化内容¶
図 6.1.12‑4に,クロスファイルインライニングオプションを指定したコンパイル方法を示す.-finline-file オプションの後に対象とするソースコードのファイル名を指定する.複数のファイル名を指定する場合は,ファイル名を ” :(コロン)” で区切って記述する.

図6.1.12‑4 クロスファイルインライニングオプションを指定したコンパイルオプション¶
(3) 性能分析¶
図 6.1.12‑5にクロスファイルインライニングオプションを指定した場合のFTRACE情報(演算コスト上位11件)を示す.
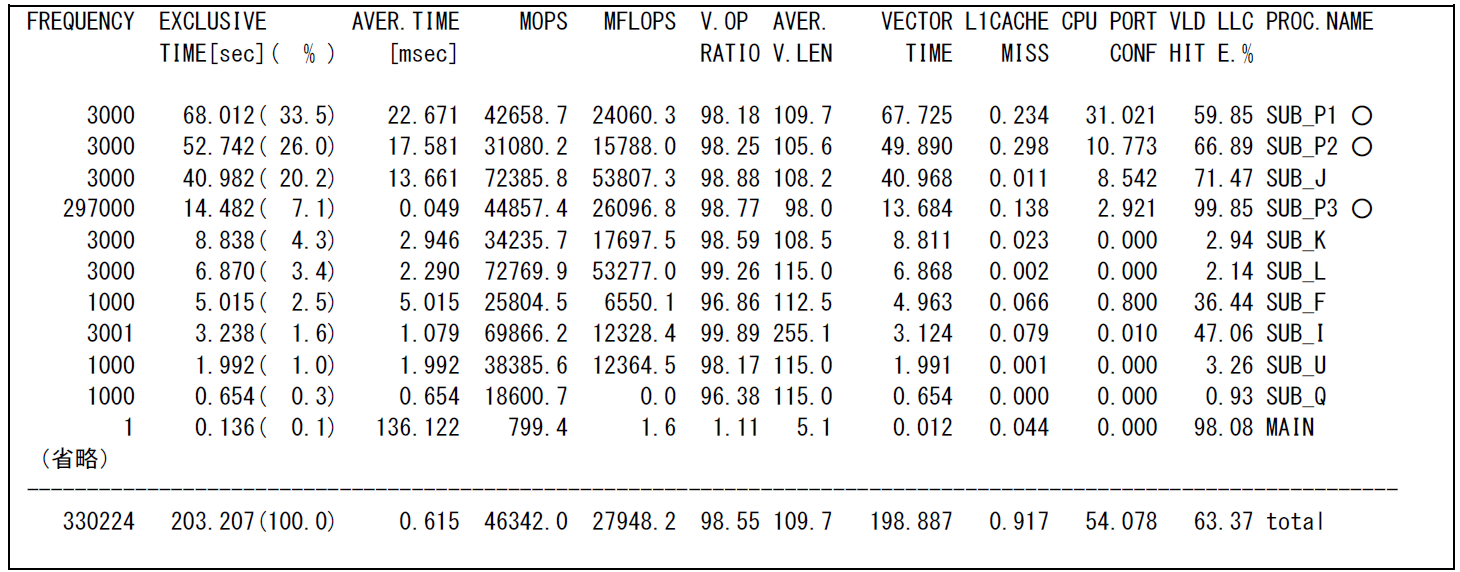
図 6.1.12‑5 クロスファイルインライニングオプションを指定後のFTRACE情報¶
クロスファイルインライニングオプションを指定したことにより,別ファイルに記述されたサブルーチンもインライン展開の対象となり,手続き呼出し回数の合計が6,011,763回から330,224回に減少した.これにより実行時間の合計が221.222秒から203.207秒に短縮されている.
クロスファイルインライニングオプションの指定による,呼び出し側サブルーチン(図 6.1.12‑5で○がついたサブルーチン)とインライン展開されたサブルーチンの関係は以下の通りである.
SUB_P1からSUB_C2,SUB_C3の呼出し
SUB_P2からSUB_C1.SUB_C4の呼出し
SUB_P3からSUB_C1の呼出し
インライン展開後の呼び出し側サブルーチンの実行時間が,インライン展開前の各サブルーチンの実行時間の合計よりも短くなり,演算時間が短縮したことが確認できる.
6.1.13. ライブラリ利用による高速化(1)¶
(1) 最適化方針¶
AOBA-Aでは,SX-Aurora TSUBASAでの計算に最適化された数学ライブラリであるNEC Numeric Library(NLC)が利用可能である.この数学ライブラリをうまく活用することで,高い性能を引き出すことができる.図 6.1.13‑1に最適化前のコードを示す.ベクトル化対象のループ内には1要素の疑似乱数値を取得する関数make_random(ユーザ定義関数)の呼び出しがあるため,ベクトル化が行われない.疑似乱数値を取得する処理をループ分割により抜き出し,該当の疑似乱数値の生成にはNLCの乱数生成ライブラリを使用することでベクトル性能を向上させる.
図 6.1.13‑2に示す最適化前のFTRACE情報では,ベクトル演算率は47.6% であり十分なベクトル性能を出すことができていない.
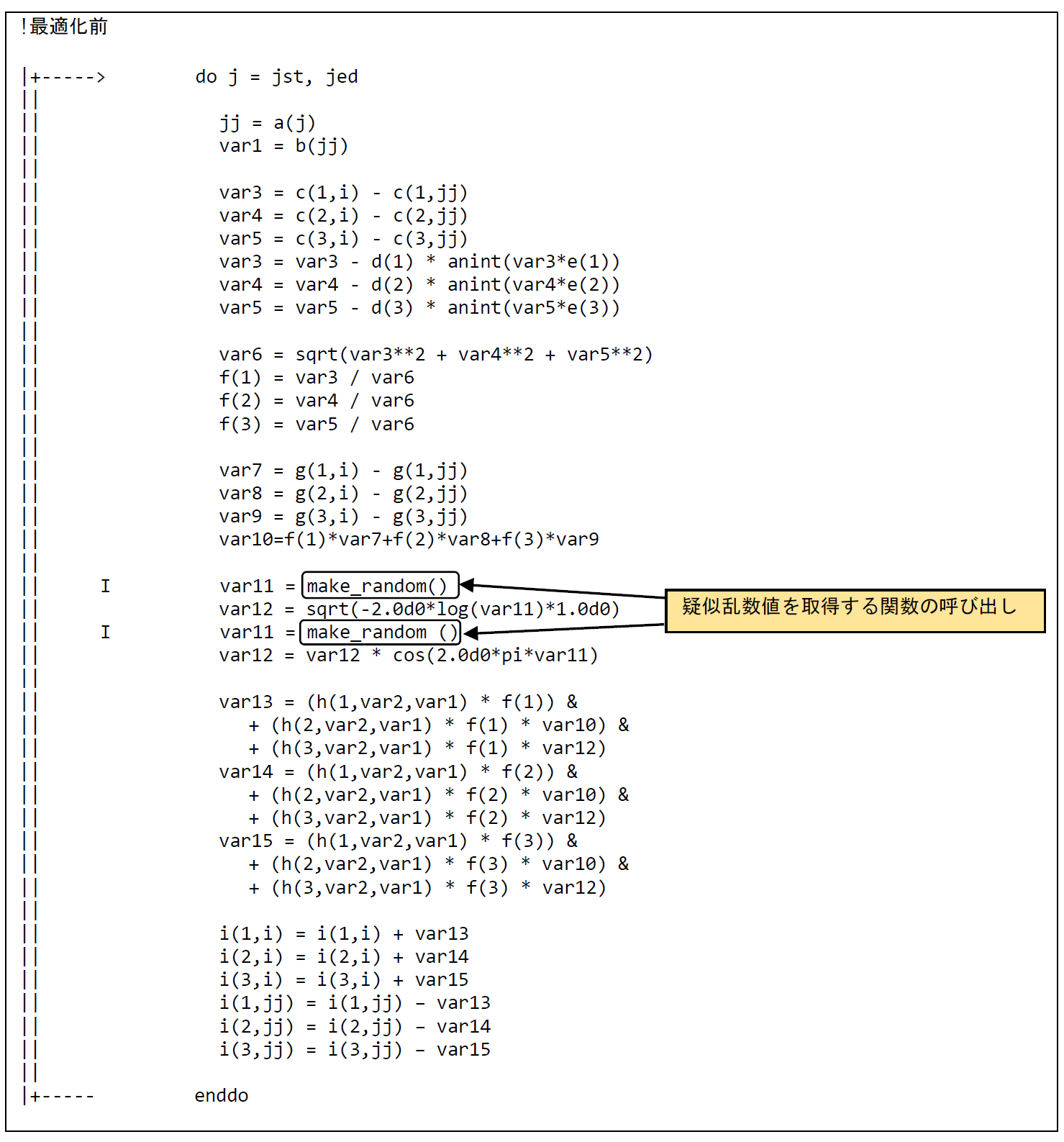
図 6.1.13‑1 ライブラリ(乱数)利用前のコード¶

図 6.1.13‑2 ライブラリ(乱数)利用前のFTRACE情報¶
(2) 最適化内容¶
図 6.1.13‑3に最適化後のコードを示す.疑似乱数値の生成処理をループ分割により抜き出し,乱数値を一時配列work1に格納し,分割した演算処理のループ内ではwork1の値を参照するように修正する.また,分割した演算処理のループにおいては,ループ内から関数呼び出しが削除されることでベクトル化の阻害要因が無くなるため,ベクトル化が行われる.更に,疑似乱数値の生成処理はNLCの乱数生成ライブラリを使用する.

図 6.1.13‑3 ライブラリ(乱数)利用後のコード¶
(3) 性能分析¶
図 6.1.13‑4に最適化前後の性能値を示す.

図 6.1.13‑4 ライブラリ(乱数)利用前後のFTRACE情報¶
ループ分割およびNLCの乱数生成ライブラリを用いることによりベクトル演算率が47.6% か87.6% に向上し,実行時間が8.5秒から0.7秒に短縮されている.
6.1.14. ライブラリ利用による高速化(2)¶
(1) 最適化方針¶
本事例は,FFT処理を高速化した事例である.図 6.1.14‑1に最適化前のコードを示す.該当処理は三次元配列に対するFFT処理を実行しているが,FFTWの一次元FFTを用いて実装されている.該当FFT処理について,一次元FFT処理から一次元多重FFT処理に変更することによりベクトル性能を向上させる.
図 6.1.14‑2にライブラリ(FFTW)利用前のFTRACE情報を示す.最適化前のFTRACE情報では,ベクトル演算率は51.7% であり十分なベクトル性能を出すことができていない.さらに,平均ベクトル長が8.2と非常に小さな値となっていることがわかる.
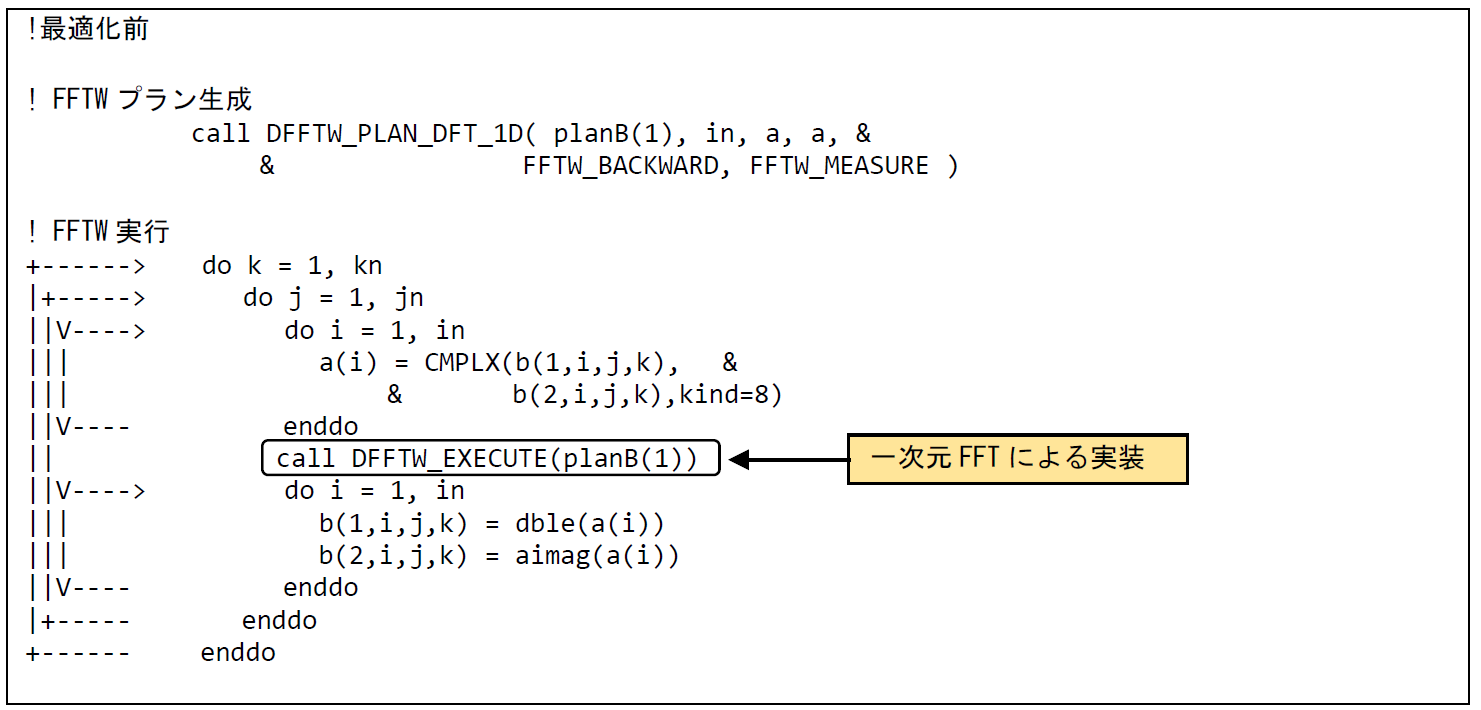
図 6.1.14‑1 一次元多重FFT利用前のコード¶

図 6.1.14‑2 一次元多重FFT利用前のFTRACE情報¶
(2) 最適化内容¶
図 6.1.14‑3に最適化後のコードを示す.一次元FFT処理から一次元多重FFT処理に変更するため,FFTWのプラン生成処理を変更する.また,一次元多重FFT処理においては,FFT処理対象となる配列を一次元配列から多重度を含めた二次元配列に変更する必要があるため,FFT処理を実行する際の一時配列を二次元配列に修正する.一次元多重FFT処理では,多重度方向がベクトル化の対象となる.この事例では,プラン生成時の第四引数であるjnが多重度の大きさとなり,その大きさは50であった.修正前の平均ベクトル長が8程度であったため,平均ベクトル長の向上も期待できる.
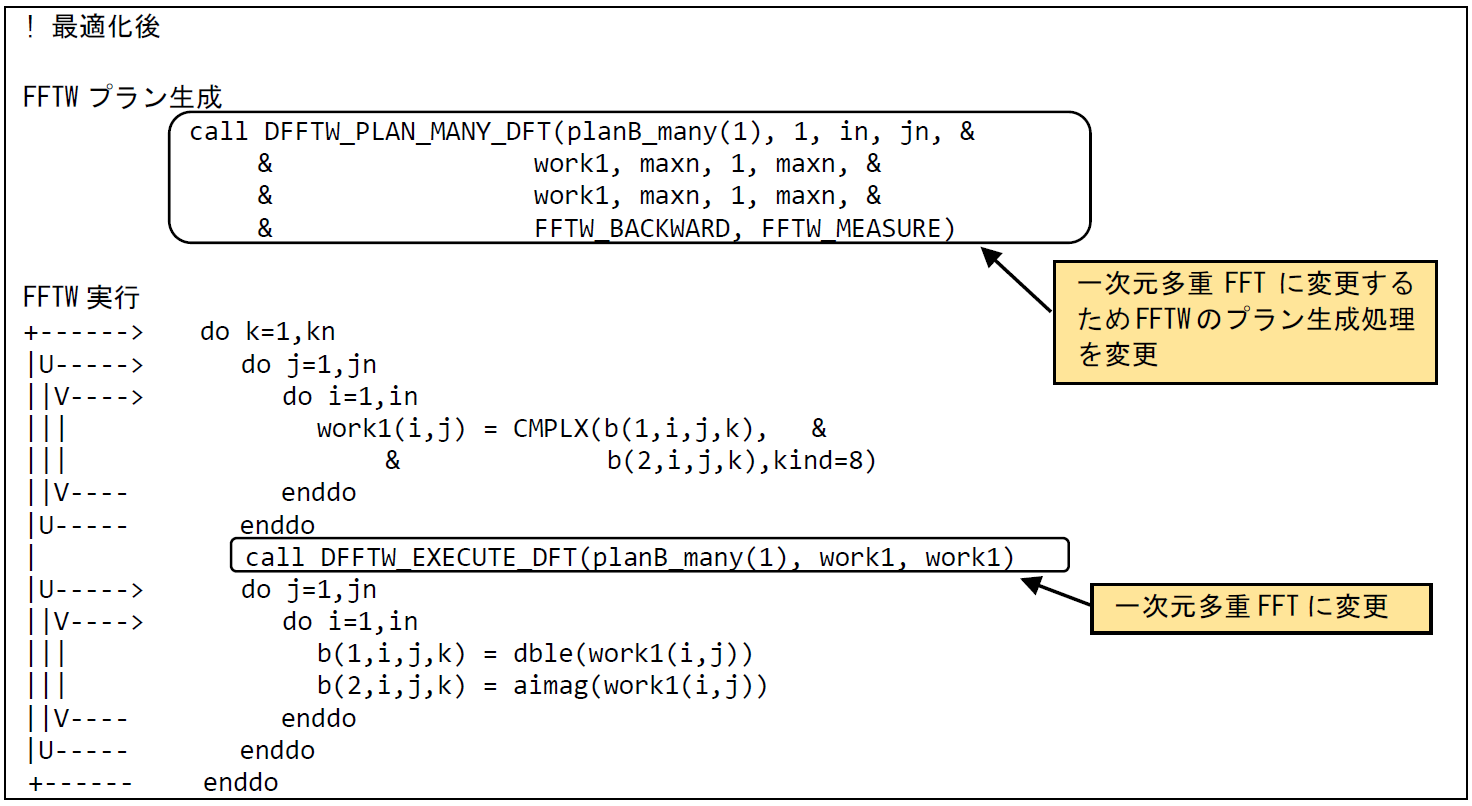
図 6.1.14‑3 一次元多重FFT利用後のコード¶
(3) 性能分析¶
図 6.1.14‑4に,最適化前後の性能値を示す.

図 6.1.14‑4 一次元多重FFT利用前後のFTRACE情報¶
一次元FFTの処理から一次元多重FFTの処理に変更することにより,ベクトル演算率は51.7 %から95.9% に,平均ベクトル長が8.2から49.9に向上し,実行時間が8.2秒から0.4秒に短縮されている.
6.2. メモリアクセス性能向上の事例¶
6.2.1. メモリアクセスパターンの変更による高速化¶
(1) 最適化方針¶
間接参照によるメモリアクセスはメモリ負荷が高いことが知られている.本事例では,メモリアクセスパターンを間接アクセスから連続アクセスに変更することでメモリ負荷を低減した最適化事例を示す.
図 6.2.1‑1に最適化前のコードを示す.本事例で使用しているプログラムは,3次元空間内の特定のセルについて計算を行う.ループ長nは計算対象のセル数を示しており,配列aには,該当するセルのX,Y,Z方向の位置情報が格納されている.そのため,まずは,それぞれのセルの位置情報を変数 i, j, k に代入し,そのあとで該当するセルの配列 cにアクセスする.つまり,配列 c の添え字 i, j, k がさらに配列 a を参照しており,間接参照の形になっている.配列cにアクセスするためには,最初に添え字i, j, k を求めるために別の配列 a にアクセスする必要があり,その結果メモリ負荷が高くなる.
アプリケーションのメモリ負荷の大きさを示す指標としてB/Fがある.B/Fとは,1つの浮動小数点演算を処理するために必要なメモリアクセス量を示し,この値が大きいほど1回の演算処理のために大量のデータをメモリから転送する必要があるといえる.しかし,必要なデータがキャッシュ上に存在する場合にはメモリにアクセスする必要はなく,キャッシュからデータを転送すればよいことになる.そこで,プログラム実行時のメモリ負荷の大きさを示す指標としてActual B/Fがある.Actual B/Fの場合,キャッシュヒットしたデータはカウントせず,実際にメモリまでアクセスしたデータのみをカウントしてB/Fを求める.Actual B/FはFTRACEの出力結果のうち,REQ. ST B/FとACT. VLD B/Fの和として計算できる.図 6.2.1‑2の最適化前のFTRACE情報から,最適化前のActual B/Fは1.6であることがわかる.AOBA-AのシステムB/Fは0.62であり,Actual B/FがシステムB/F以上である場合,そのプログラムのメモリ負荷は高いといえる.
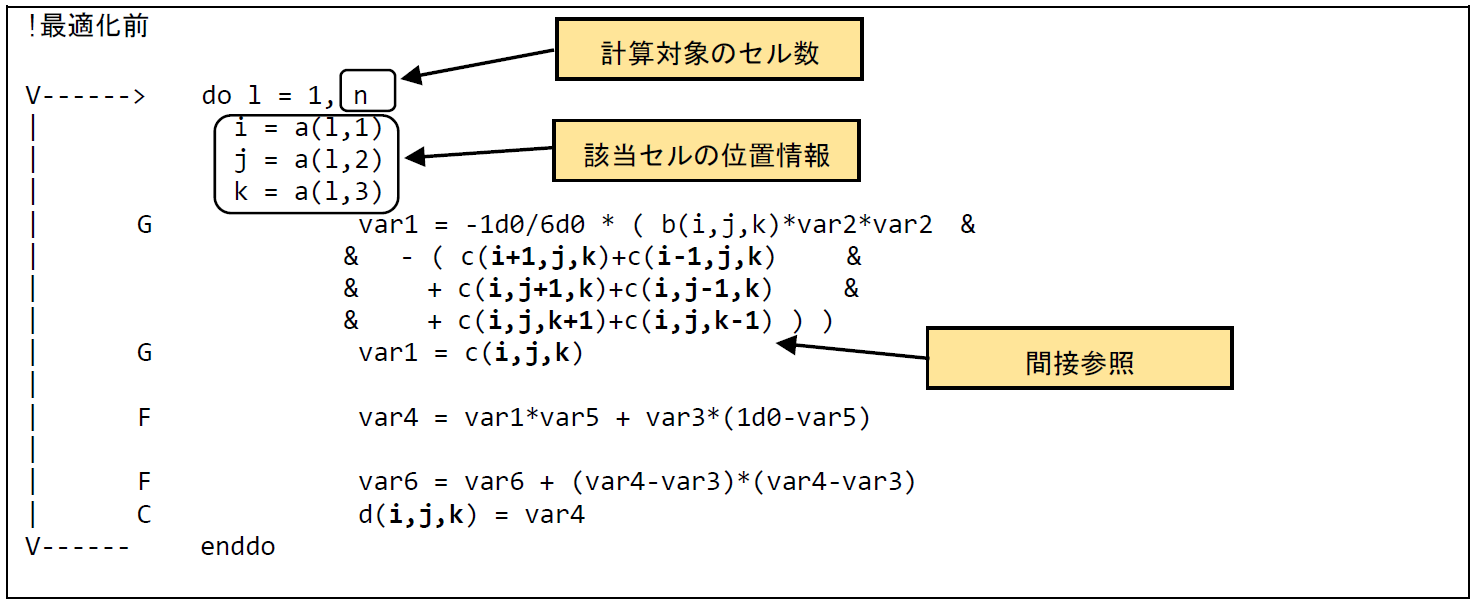
図 6.2.1‑1 メモリアクセスパターン変更前のコード¶

図 6.2.1‑2 メモリアクセスパターン変更前のFTRACE情報¶
(2) 最適化内容¶
図 6.2.1‑3に最適化後のコードを示す.ist,iedはX方向の全領域を示しており,同様にjst,jed,kst,kedはY,Z方向の全領域を示す.つまり,最適化後のコードは,計算対象のセルだけにアクセスするのではなく,3次元空間内の全セルにアクセスしている.計算対象のセルについては事前に配列work1の値に,0より大きい値を設定しておくことで,計算時に配列work1の値で計算対象のセルかどうかを判断している.最適化後のコードではメモリアクセスのパターンが連続アクセスとなるため,メモリ負荷を低減することができる.
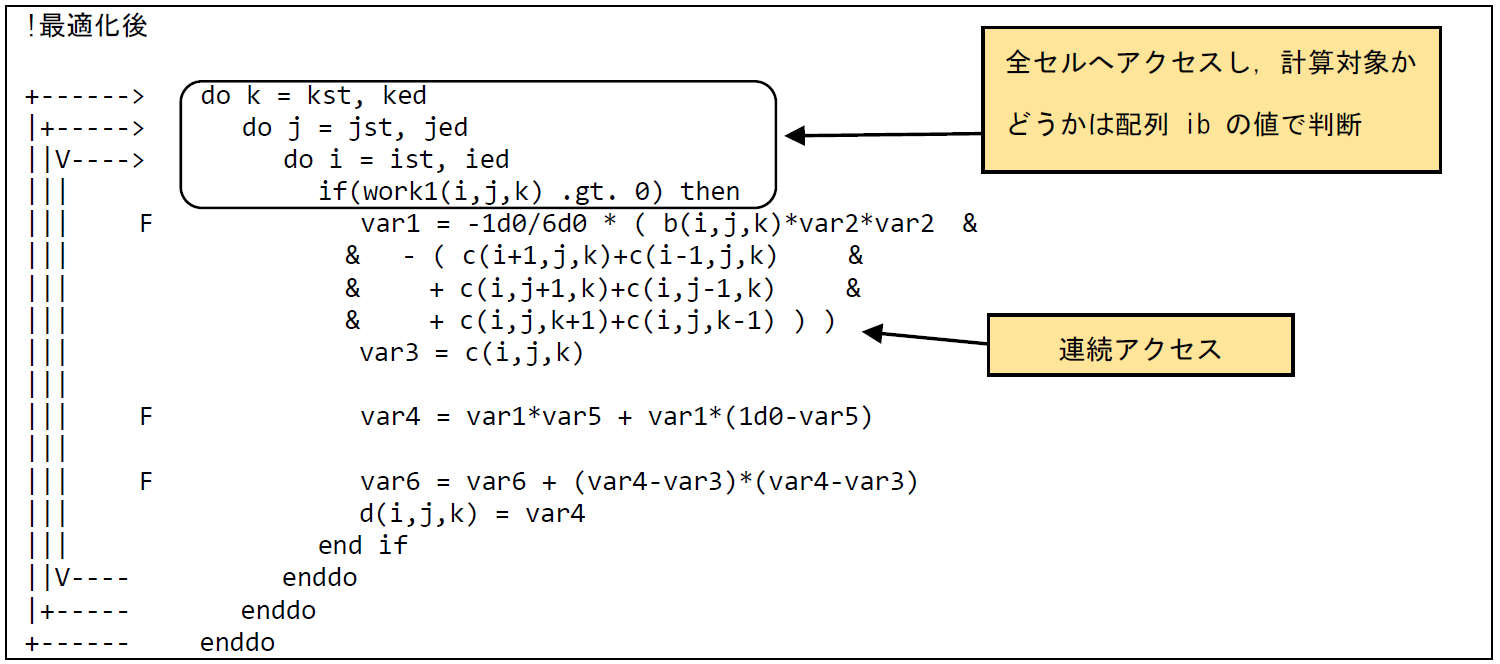
図 6.2.1‑3 メモリアクセスパターン変更後のコード¶
(3) 性能分析¶
図 6.2.1‑4に最適化前後の性能値を示す.

図 6.2.1‑4 メモリアクセスパターン変更前後のFTRACE情報¶
メモリアクセスパターンを変更することで,Actual B/Fが1.6から1.07に減少し,実行時間が627.1秒から166.7秒に短縮されている.
6.2.2. メモリアクセス効率化による高速化¶
(1) 最適化方針¶
多重ループのループ順を入れ替えることで,性能が大きく向上する場合がある.例えば,最内側ループ(ベクトル化対象ループ)のループ長が外側ループのループ長に比べて極端に小さい場合,ループを入れ替えることで,ベクトル長が長くなり性能の改善が期待できる.このように,多重ループのそれぞれのループのループ長に極端な違いがある場合には,どのループをベクトル化の対象とすれば性能を引き出せるか容易に検討することができる.一方で,ループ長に大きな違いがない場合には,配列へのアクセスパターンの違いにより性能が変化すると考えられる.本事例では,多重ループのループ長がすべて同じだった場合に,最適なループ順番を検討した事例である.
図 6.2.2‑1に最適化前のコードを示す.3つの三重ループ(ループ1,ループ2,ループ3)は,ループ長がすべて128であるが,配列のアクセスのパターンが異なっている.例えば,ループ1の場合,ベクトル化されたループのループ変数iは,ロードする配列cについて1次元目にアクセスするため,連続アクセスとなる.一方で,ストアする配列aに関しては3次元目にアクセスするためストライドアクセスとなる.ループ2,ループ3に関してはロードする配列がストライドアクセス,ストアする配列が連続アクセスとなる.
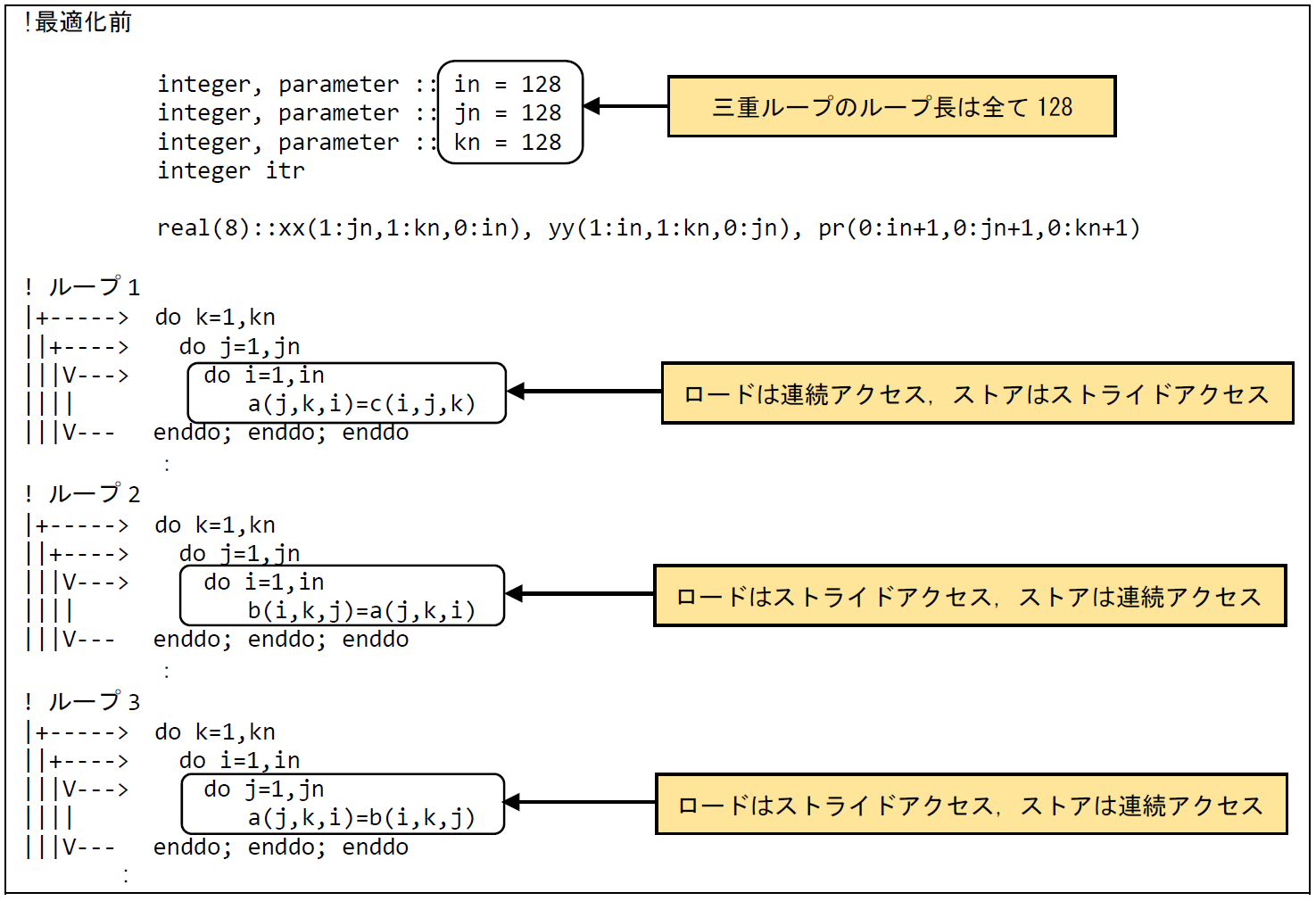
図 6.2.2‑1 メモリアクセスの効率化前のコード¶
(2) 最適化内容¶
多重ループ内でロード配列,ストア配列へのアクセスパターンが異なる場合には,以下の点に注意して最適なループ順を検討する.
① ロード,ストアの配列アクセスにおいて,高次元目をベクトル化の対象としない.
② ストア配列へのアクセスにおいてメモリ負荷が小さくなるようにする.
図 6.2.2‑2に最適化後のコードを示す.まずループ1については,①の条件からロード配列c,ストア配列aの3次元目がベクトル化の対象とならいようにするため,iおよびkのループが最内側ループとならないようにする.さらに②の条件からなるべくストア配列の配列アクセスの負荷が小さくなるように考慮すると,ループの順番は外側から i, k, j の順番となる.同様に,ループ2,ループ3について上記条件を考慮すると,ループ2では,外側から j,i,k,ループ3では外側から i,j,k のループの順番が最適と考えられる.

図 6.2.2‑2 メモリアクセスの効率化後のコード¶
(3) 性能分析¶
図 6.2.2‑3に最適化前後の性能値を示す.ループ順を入れ替えたすべてのパターンの性能値を記載しており,PROC.NAMEに記載されたijkの順番がループ順をあらわす.例えば loop1-kjiは,最外側ループがkのループ,最内側ループがiのループのように,左に行くほど外側のループであることを示している.
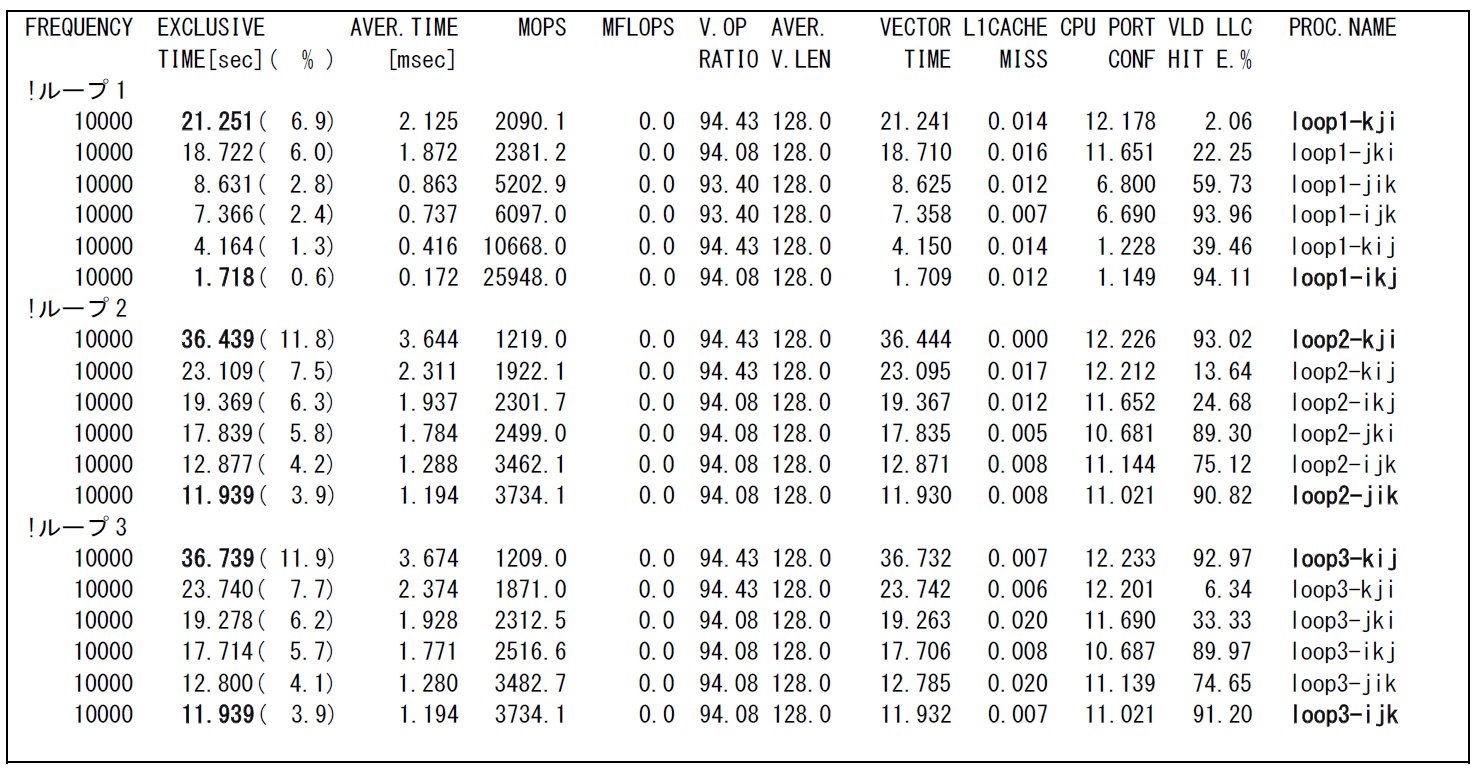
図 6.2.2‑3 メモリアクセスの効率化前後のFTRACE情報¶
すべてのループにおいて,最適化後の性能値が最も高くなっていることがわかる.特にループ1では実行時間が21.25秒から1.72秒と約12倍短縮されている.
ただし,ループ長の違いやループ内の配列の数の違いなどにより,キャッシュの動作が変化するとメモリアクセス性能も影響を受ける.つまり,本事例で検討した最適化の方は,必ずしもどんなパターンにおいても成立するとは限らない点には注意が必要である.あくまで多重ループのループ順番最適化の参考情報として活用してほしい.
6.2.3. ループアンロールによる高速化¶
(1) 最適化方針¶
多重DOループでステンシル計算(ストアとロードに配列のインデックスが近い値が用いられる時間発展型の演算)となっている場合,多重ループのアウターアンロールによりメモリアクセス数の削減を図れることが多い.
本事例は outerloop_unroll(n) 指示行の追加により多重ループのアンローリングを行うことでメモリアクセス数の低減を行う手法である.図 6.2.3‑1に最適化前のコードを示す.配列aの演算において,最内ループは3次元目のiのインデックスでベクトル化されている.その外側のループは2次元目のjのインデックスの演算を行い,j-1, j, j+1 がロードされ,jにストアされるステンシル計算となっている.
図 6.2.3‑2に示したFTRACE情報から,ベクトル演算率,平均ベクトル長ともに高い値となっており,ベクトルプロセッサの性能を十分に発揮したプログラムであることが分かる.またREQ.ST B/Fの値が3.20,REQ.LD B/Fの値が6.40と高く,高いメモリアクセス性能を必要とするプログラムであることが分かる.
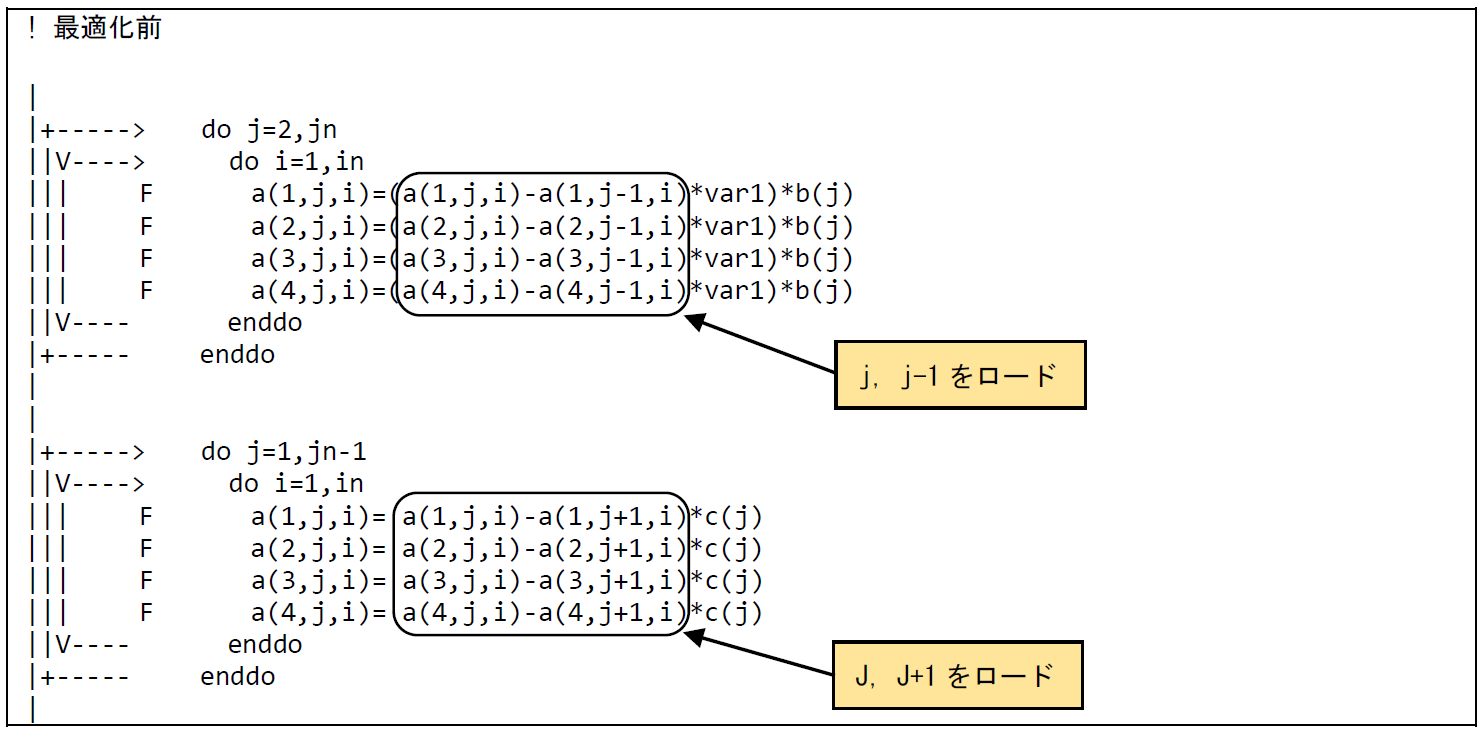
図 6.2.3‑1 ループアンロール前のコード¶

図 6.2.3‑2 ループアンロール前のFTRACE情報¶
(2) 最適化内容¶
図 6.2.3‑3に最適化後のコードを示す.アウターアンロールを行うインデックスjのDOループの前に指示行 outerloop_unroll(n) を追加することで,インデックスjのループにアンロールされたことを示す ”U” が記載されたことが確認できる.アンロール段数はnを超えない最大の2のべき乗数となる.本事例ではnに2〜16の値を指定して実行し,最も実行時間の短縮されたn=4を採用した.

図 6.2.3‑3 ループアンロール後のコード¶
(3) 性能分析¶
図 6.2.3‑4に最適化前後の性能値を示す.

図 6.2.3‑4 ループアンロール前後のFTRACE情報¶
outerloop_unroll(n)指示行により外側ループをアンロールしたことでメモリ負荷が下がり,REQ.LD B/F(Required Load B/F)が6.40から4.04に減少している.必要とされるメモリロードが減ることでメモリアクセス時間が減少した結果,実行時間が20.9秒から15.6秒に短縮されている.
6.2.4. メモリ割当回数低減による高速化¶
(1) 最適化方針¶
図 6.2.4‑1に最適化前のソースコードを示す.本事例は,粒子法の一種であるSmoothed Particle Hydrodynamics (SPH法)に基づくミニアプリケーションである,SPH-EXA (https://github.com/unibas-dmi-hpc/SPH-EXA) より抜粋したものである.本コード片は粒子をMPIプロセスに割り当てるため,各粒子がシミュレーション空間内のどの領域に存在するか計算する, distributeParticles関数の一部である.
このコードでは,各領域に属する粒子IDのリストであるcellListを粒子の座標に応じて構築している.cellList[l]は,l番目の領域に属する粒子IDのリストである.各領域内の粒子数は可変のため,vector<T>の末尾に要素を追加する関数vector<T>::push_backを使用し,逐次的にcellListを構築している.しかし,push_backは動的にメモリ領域の拡張をするため,要素を追加するたび境界チェックを行うため,ベクトル化を阻害してしまう.そこでcellList[l]の長さ,すなわち領域内の粒子数を事前に計算し,メモリ領域を確保しておくことで,push_backの呼び出しを回避する.
図 6.2.4‑2にFTRACE情報を示す.ベクトル化率が非常に低いことが明らかである.また,Reallocateという,メモリの再割当を行うと推定される関数が1,200万回以上も呼び出されていることもわかった.

図 6.2.4‑1 リサイズ回数低減前のソースコード¶

図 6.2.4‑2 リサイズ回数低減前のFTRACE情報¶
(2) 最適化内容¶
図 6.2.4‑3に 最適化後のソースコードを示す.push_back関数の呼び出しを避けるため,次の3ステップに分けて処理を実現する.すなわち,(1) cellListの各要素のリストの長さを事前に計算 (2) cellListの各要素のリストをリサイズしメモリ領域を確保 (3) cellListの各要素のリストに粒子IDを代入,である.
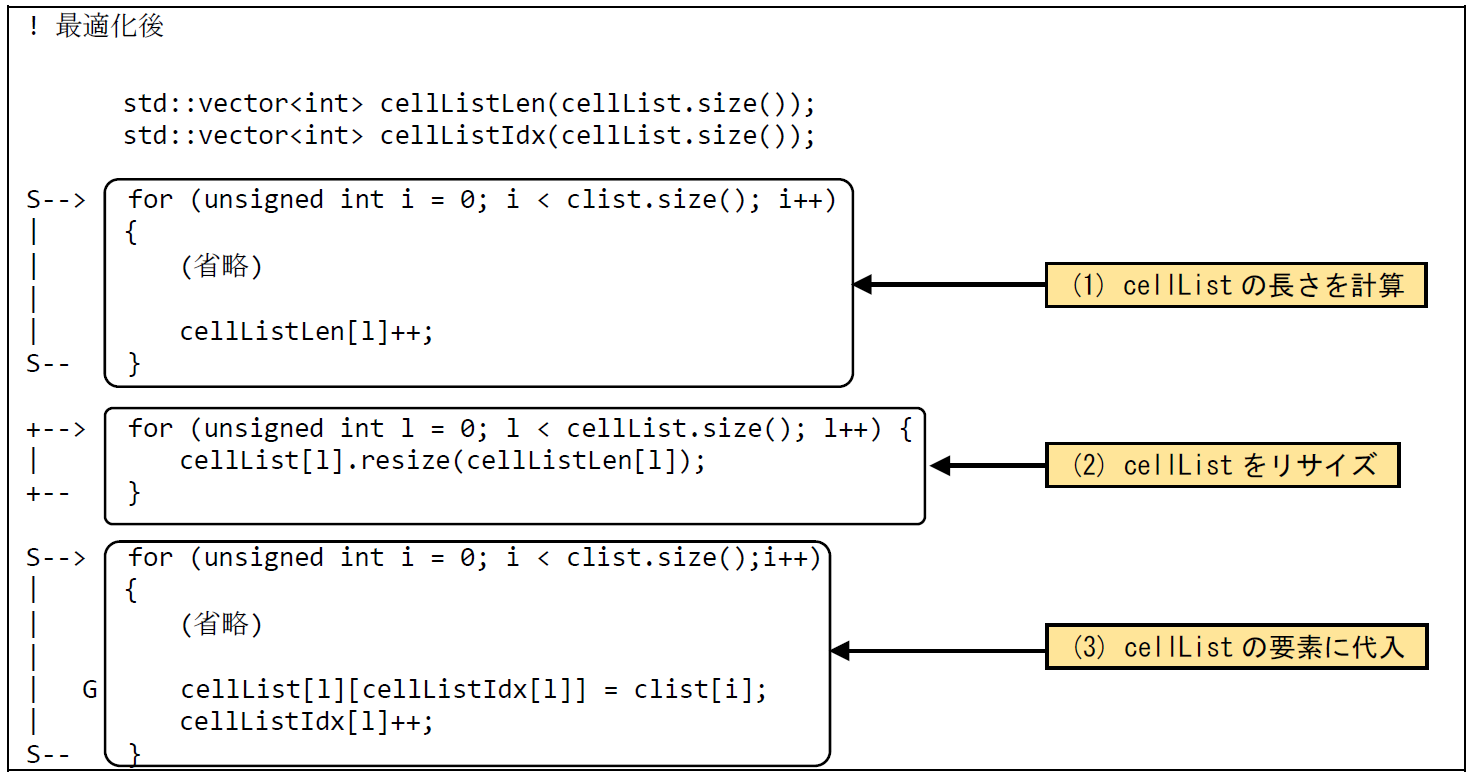
図 6.2.4‑3 リサイズ回数低減後のソースコード¶
(3) 性能分析¶
図 6.2.4‑4に最適化後のFTRACE情報を示す. また,図 6.2.4‑5にリサイズ回数低減前後のReallocate関数の実行回数の差異を記載する.

図 6.2.4‑4 リサイズ回数低減前後のFTRACE情報¶

図 6.2.4‑5 リサイズ回数低減前後のReallocate関数の実行回数¶
最適化により,実行時間が33.3秒から2.7秒に短縮されている.また,部分ベクトルによってベクトル化率が0.03% から35.29% に向上した.また,Reallocate関数の実行回数が1,200万回程度から440万回程度まで削減されていることがわかる.
6.3. ファイルI/O高速化の事例¶
6.3.1. ファイルI/Oの高速化¶
(1) 最適化方針¶
AOBA-Aでサイズの大きいデータの入出力を行う場合はI/O時間短縮のため,書式なし記録(バイナリファイル)を行うことが推奨される.これは,書式付記録(テキストファイル)でI/Oを行った場合,データの書き出し要素毎に書式変換のためのスカラ処理が必要となるため,著しく実行時間が増加するためである.
本事例は書式なし記録の場合でも,WRITE/READ文における配列のアクセス方法がスカラ方式の場合には入出力の時間が増加するため,これを配列範囲の指定に変更しベクトル演算とすることで計算時間の短縮を図る.また,Fortran2003から実装されたファイルI/Oの方式でC言語とも互換性のある,ストリームファイルの書式なし記録でI/Oを行った場合の性能も示す.
FTRACE情報の取得の際に,環境変数 VE_FORT_FILEINF=DETAIL を指定して実行する事で,ファイルI/Oに関連する情報(File Information)を採取する事が可能である.図 6.3.1‑1に最適化前のコードを示す.倍精度実数で定義された3つの3次元配列のWRITEおよびREADを行い,一度のI/Oにおけるデータサイズは402,653,184byte(384MB)となる.外部ファイルの接続方法は順編成ファイルの書式なし記録(unformatted, sequential)である.
図 6.3.1‑2に最適化前のFTRACE情報を,図 6.3.1‑3に最適化前のFile I/O情報の一部を示す.ファイルは書式なし記録で行われているが,WRITE/READ文での配列のアクセス方法がスカラ方式となるため,WRITE/READともにベクトル演算率が低く,その結果ファイル転送速度(Transfer Rate)はWRITEで約150,959KByte/sec,READで約78,337KByte/secとなっている.

図 6.3.1‑1 最適化前のコード¶

図 6.3.1‑2 最適化前のFTRACE情報¶
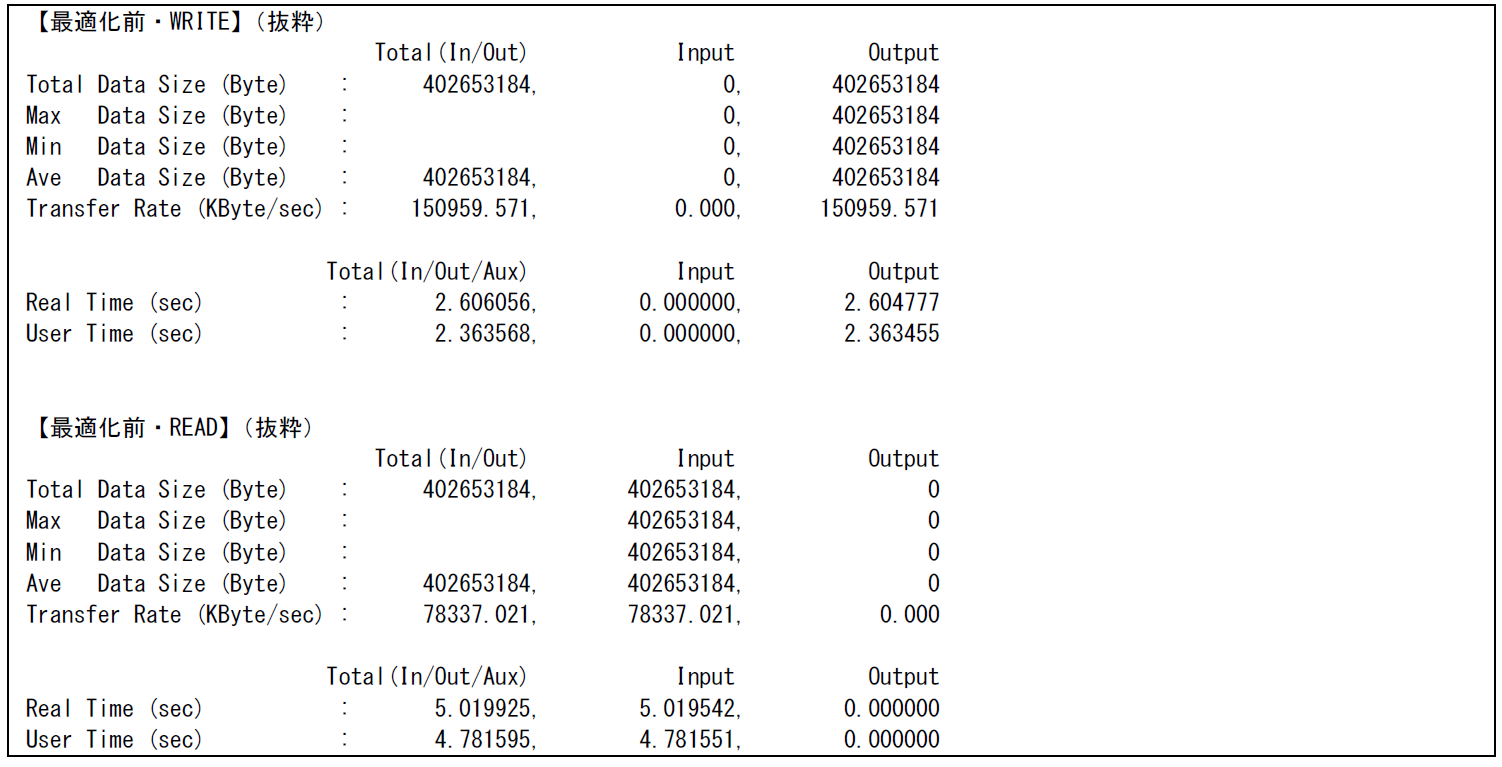
図 6.3.1‑3 最適化前のFile I/O情報¶
(2) 最適化内容¶
図 6.3.1‑4に最適化後のコードを示す.WRITE/READ文において配列のアクセス方法を配列範囲を指定する方法に変更している.また,図 6.3.1‑5は accsess='stream' を指定してストリーム方式でのファイルI/Oを行うコードである.

図 6.3.1‑4 最適化後のコード¶

図 6.3.1‑5 access='stream'を指定したコード¶
(3) 性能分析¶
図 6.3.1‑6に最適化前後およびストリーム方式でのファイルI/Oを行った場合のFTRACE情報を,図 6.3.1‑7に最適化後のFile I/O情報,図 6.3.1‑8にストリーム方式でのFile I/O情報を示す.
最適化後はファイルI/Oがベクトル演算で行われたことにより,ベクトル演算率が約99% まで増加し,計算時間はほぼ0秒となった.このときのファイル転送速度はWRITEで約2,894,875KByte/sec,READで約3,579,814KByte/secとなり,最適化前と比較してそれぞれ約19倍と約45倍の性能向上となった.
ストリーム方式でのI/Oの場合,ファイル転送速度はWRITEで約2,952,594KByte/sec,READで約9,514,898KByte/secとなり,最適化後と比較してWRITEではほぼ同等の性能であったが,特にREADでは約2.6倍のさらなる性能向上がみられた.
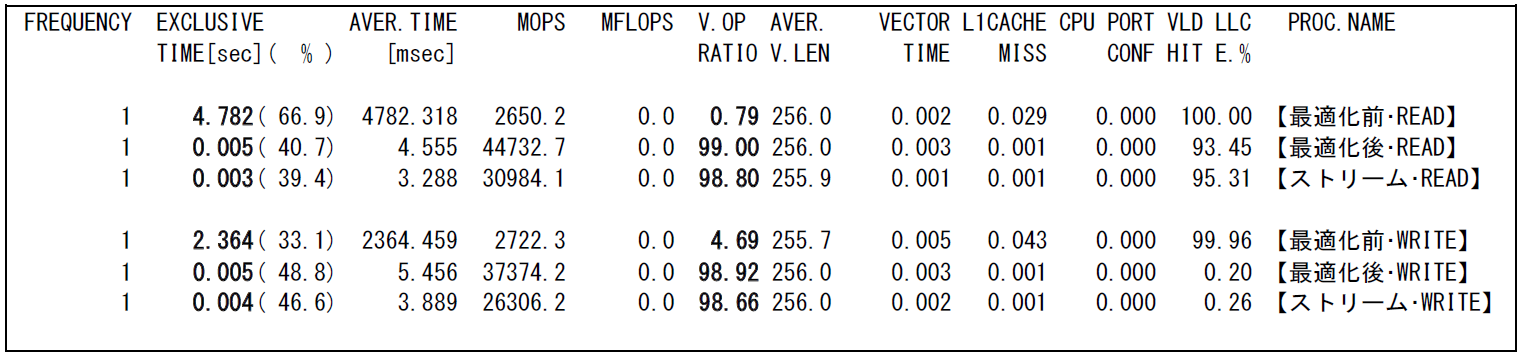
図 6.3.1‑6 最適化前後のFTRACE情報¶
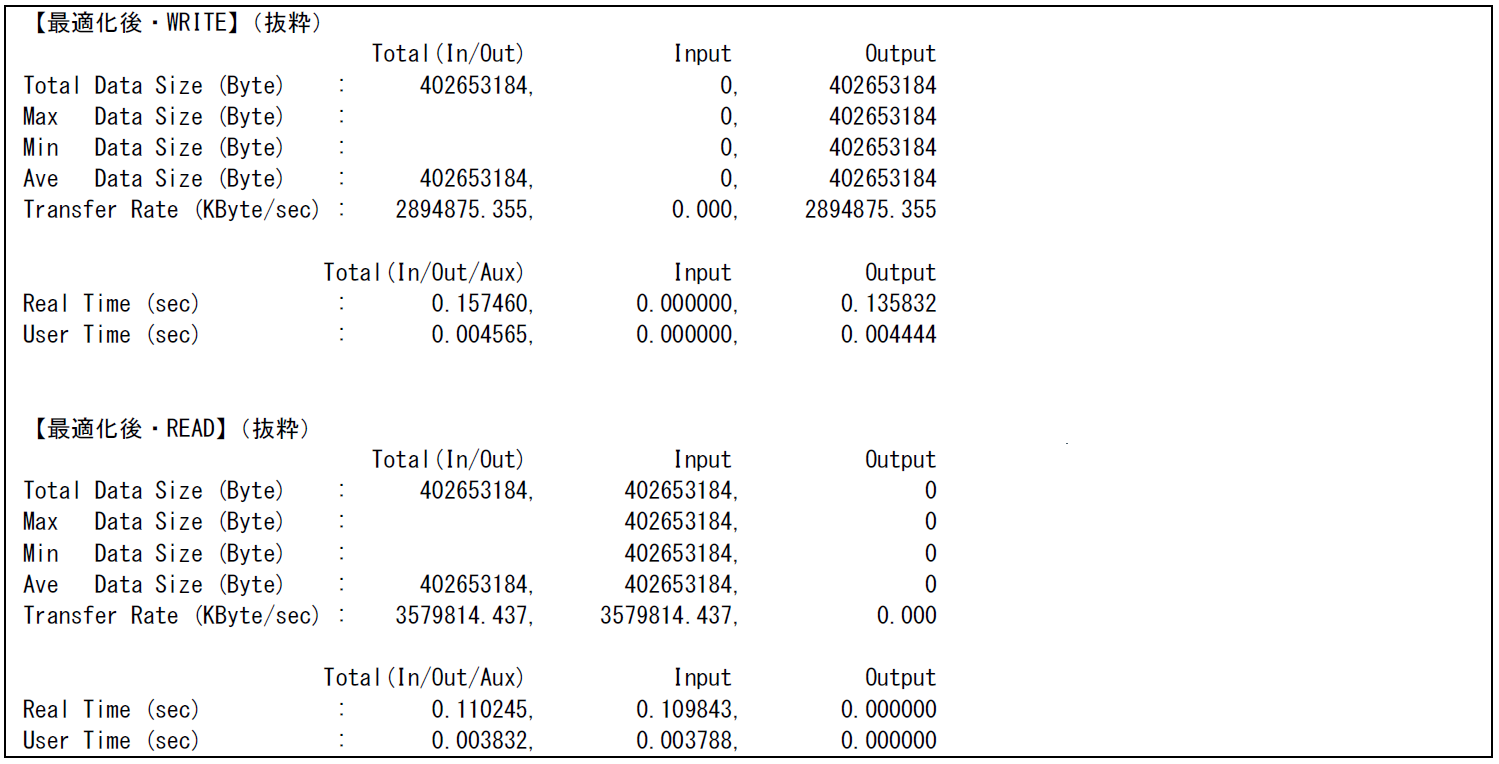
図 6.3.1‑7 最適化後のFile I/O情報¶
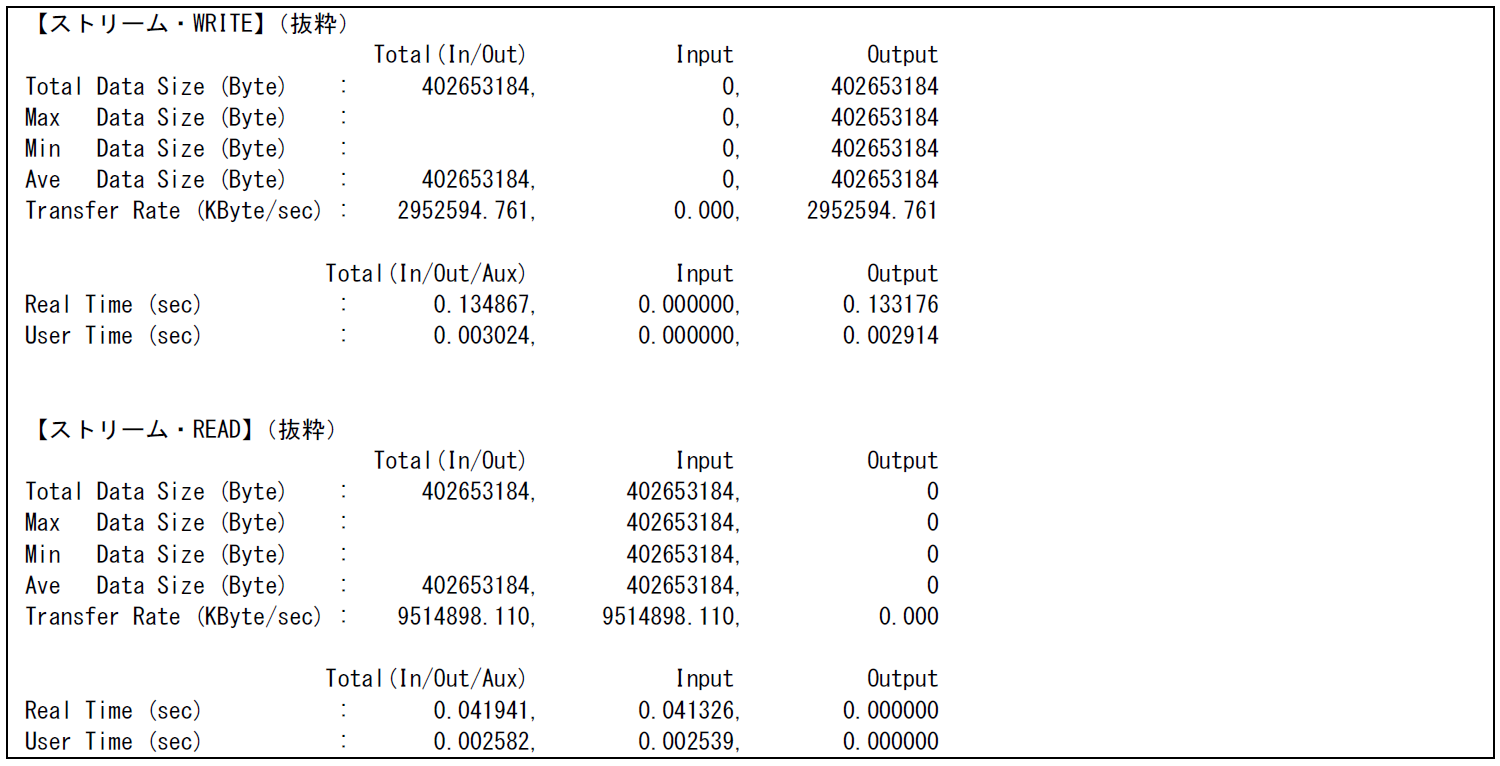
図 6.3.1‑8 ストリーム方式でのFile I/O情報¶
6.4. MPI通信処理改善による高速化の事例¶
6.4.1. 複数の通信処理をまとめることによる高速化¶
(1) 最適化方針¶
本事例は,MPI通信処理を削減することで高速化を行った例である.
図 6.4.1‑1に最適化前のコードを示す.MPIプロセス毎に変数var[1-6]が個別に算出され,それぞれについてMPI_Allreduce通信処理が行われている.その後,変数var7が(MPI_Allreduce通信によって得られた)全MPIプロセス合計のvar[1-6]の総和として算出されている.後続の処理で参照されるのはvar7のみである.
MPIプロセス毎にvar[1-6]の総和を算出し,その値についてMPI_Allreduce通信を行うことでMPI通信回数を削減することができる.
図 6.4.1‑2に示す最適化前のFTRACE情報では,10,800回のMPI通信によって合計84.4 kByteがMPI通信の対象となっている.MPI通信回数を削減することで性能向上が期待できる.
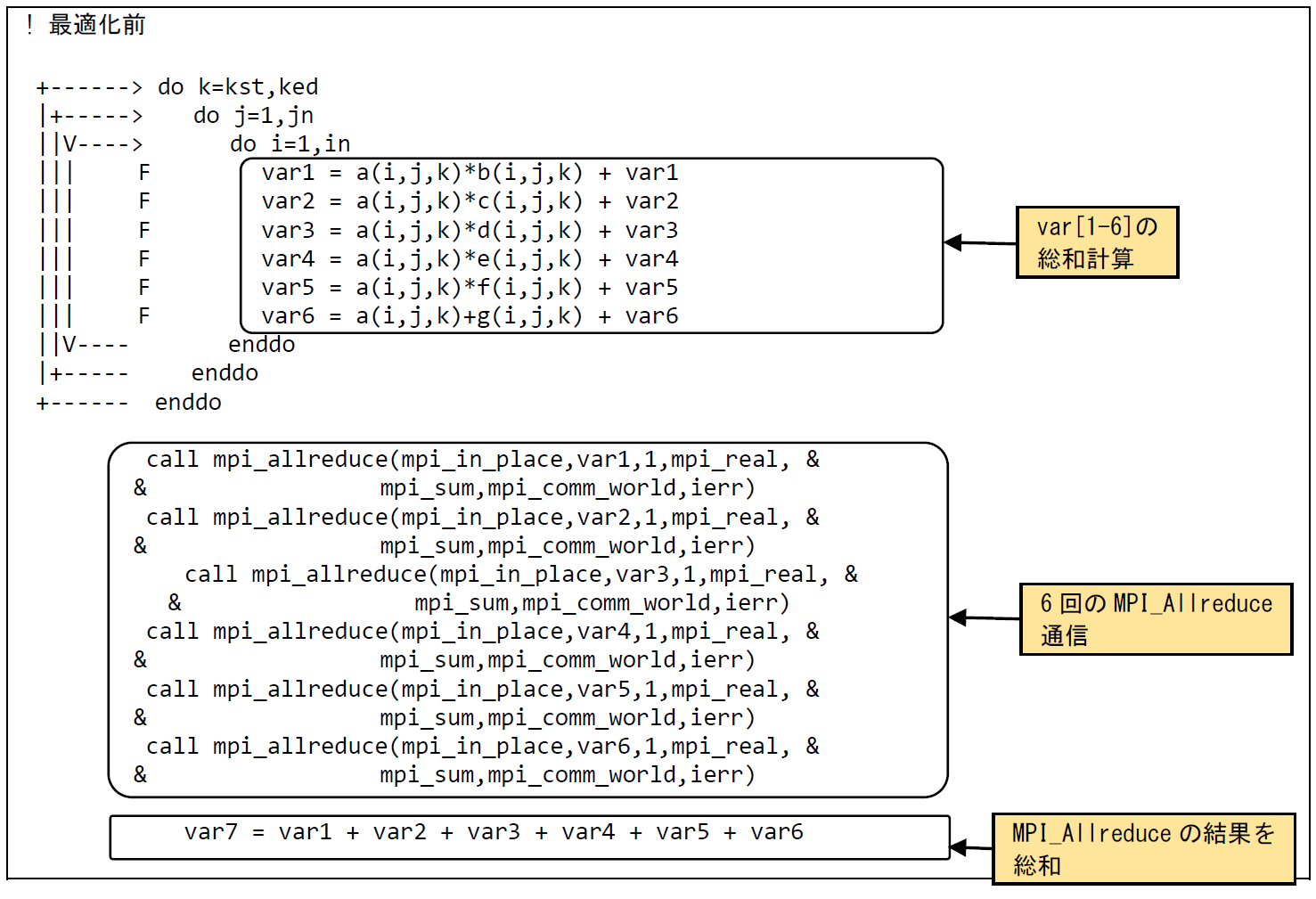
図 6.4.1‑1 最適化前のコード¶

図 6.4.1‑2 最適化前のFTRACE情報¶
(2) 最適化内容¶
図 6.4.1‑3に最適化後のコードを示す.MPIプロセス毎にvar[1-6]の総和を算出し,その値についてMPI_Allreduce通信を行うことでMPI通信回数を削減することができる.
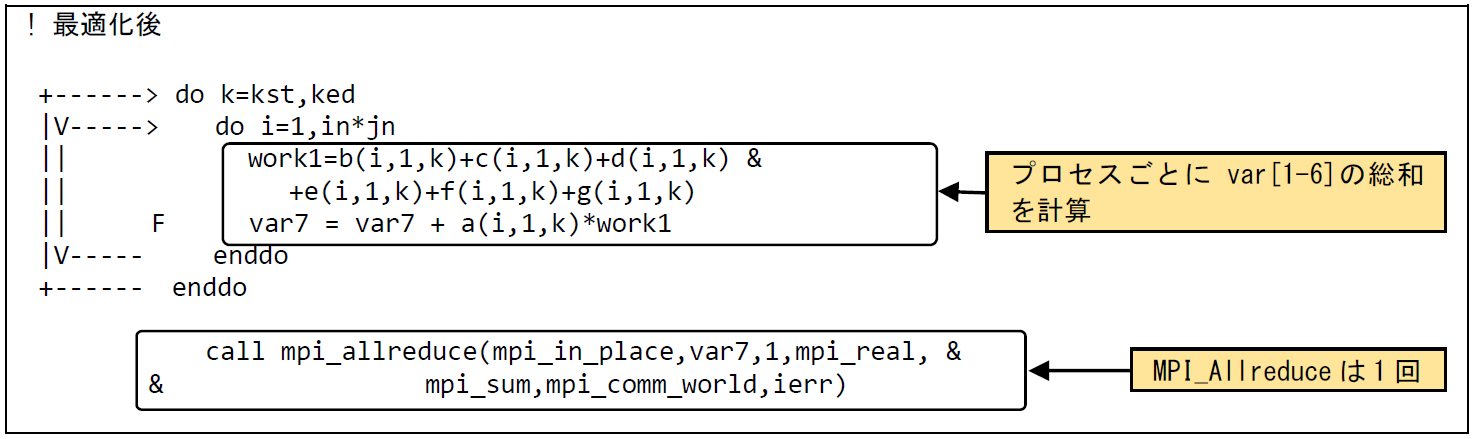
図 6.4.1‑3 最適化後のコード¶
(3) 性能分析¶
図 6.4.1‑4に最適化前後の性能値を示す.
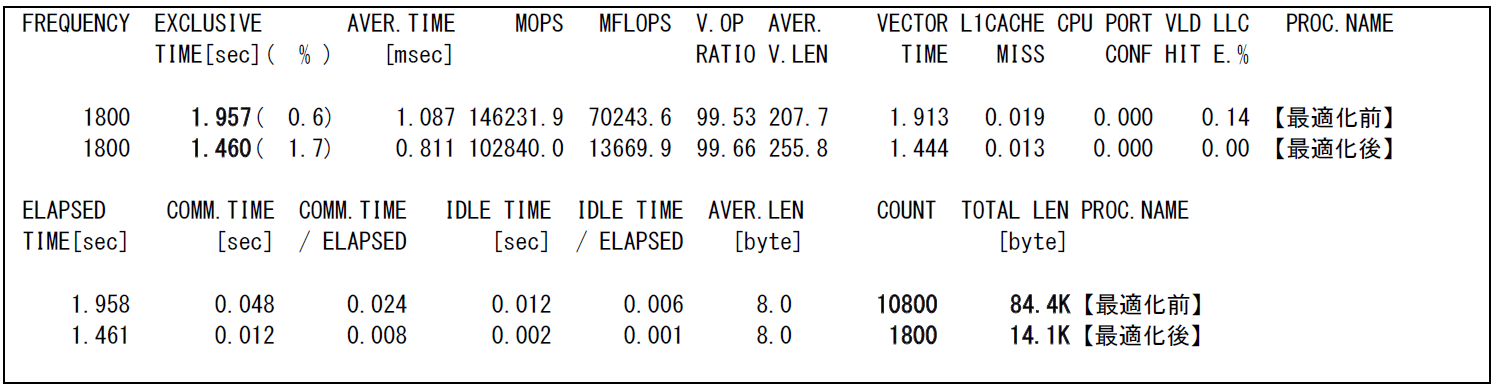
図 6.4.1‑4 最適化前後のFTRACE情報¶
MPI通信回数の削減により,MPI通信回数が10,800回から1,800回に,MPI通信量が84.4 kByteから14.1 kByteに削減されている.結果として実行時間が2.0秒から1.5秒に短縮されている.
6.4.2. 演算と通信のオーバーラップによる高速化¶
(1) 最適化方針¶
MPIの通信処理時間を削減する手法として,演算処理とのオーバーラップがある.演算処理と同時にMPI通信処理を実行することで,通信処理時間を隠蔽するものである.この手法の適用可能な条件として,通信処理に依存しない(直接関係のない)演算処理が存在する必要がある.例えば,差分計算をMPI化する場合,各MPIプロセスに割り当てられた領域のうち,境界領域については,隣接するMPIプロセスとデータ交換が必要になる.この場合,データ交換が必要な境界領域を先に演算し,データ交換の必要ない境界領域以外の演算中にデータ交換(MPI通信処理)を行うことで,演算と通信のオーバーラップを実現可能である.
本高速化では演算と通信のオーバーラップの手法として,スレッド操作を用いる.MPI並列とスレッド並列を組み合わせたハイブリッドMPI実行(VE間はMPI並列,VE内はスレッド並列)において,演算処理に必要なデータのメモリからの供給が間に合わず,演算処理が待ち状態となりスレッド並列の効果が得られない場合がある.このような場合に,特定のスレッドがMPI通信処理を担当し,演算処理を担当する他のスレッドと平行に実行することで演算処理と通信処理のオーバーラップを実現する.
図 6.4.2‑1(左)に演算処理と通信処理をオーバーラップさせない場合の処理フローを示す.MPIプロセスに割り当てられた全領域の計算をスレッドに割り当て,各スレッドが並列に演算処理を実行する.演算処理が終了すると,隣接する領域間で境界要素の交換を行うため,境界要素を収集する処理を実行する.次に,収集したデータを隣接する領域を担当するMPIプロセス間で交換するための通信処理を行う.SX-Aurora TSUBASAのMPIは,どのスレッドもMPI手続きを呼び出すことができるが,複数のスレッドが同時にMPI手続きを実行することはできないため(MPI_THREAD_SERIALIZED機能),境界領域の通信はマスタースレッド(スレッド0)が担当して実行する.通信処理終了後,通信されたデータをもとの配列に格納する境界要素の展開処理を実行する.図 6.4.2‑1(右)に,演算処理と通信処理をオーバーラップさせた場合の処理フローを示す.まず,境界領域の計算を全スレッドで分担して実行する.次に,マスタースレッドが境界要素の収集,データ交換のための通信,交換された境界要素の展開を担当する.そのほかのスレッド(スレッド1から3)は境界領域以外の計算を分担して担当する.このとき,スレッドに対する割り当て方法は,OpenMPが有するschedule機能を用いて自動で設定する.
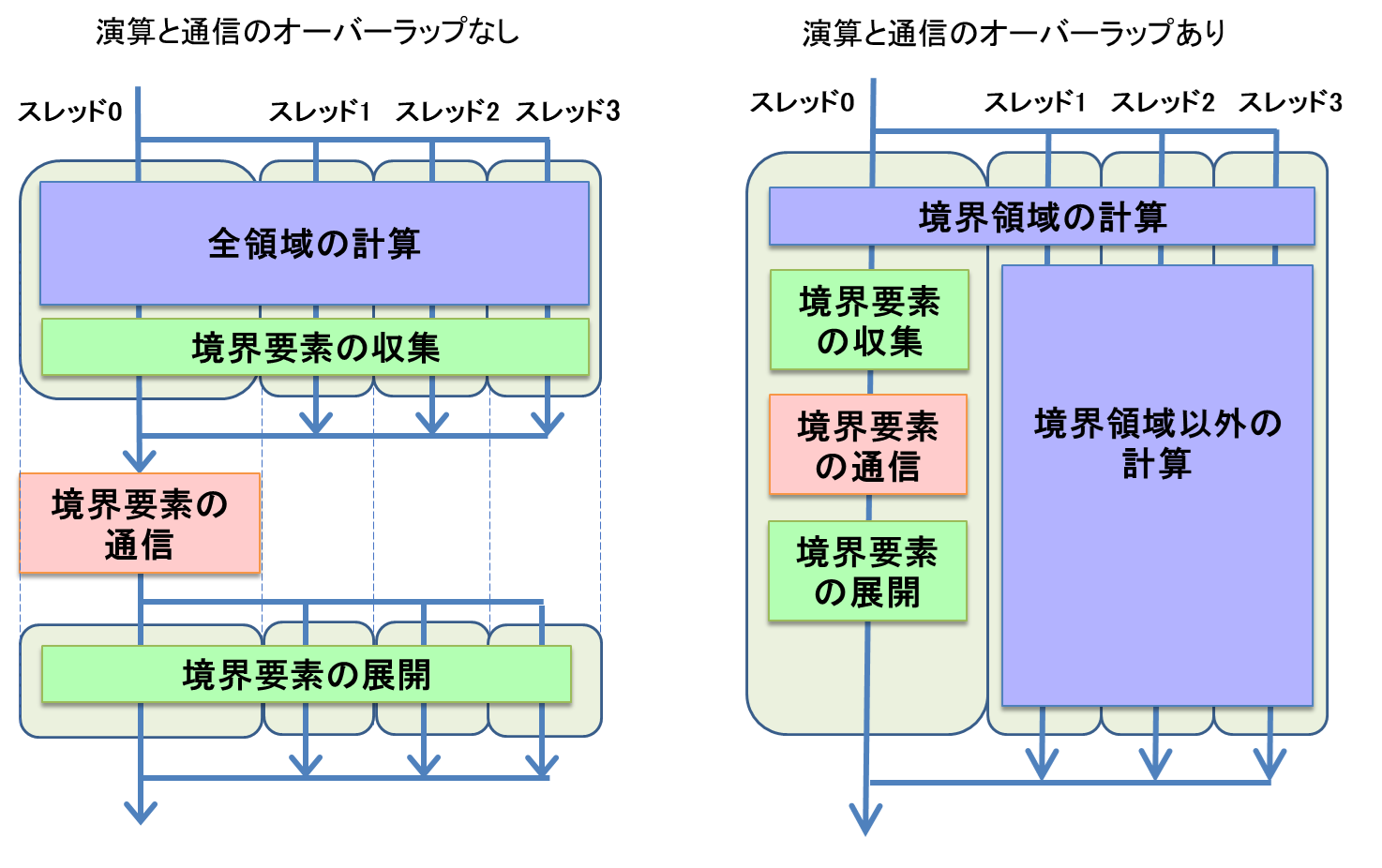
図 6.4.2‑1 演算と通信のオーバーラップなし(左)とあり(右)の処理フロー¶
演算処置と通信処理をオーバーラップさせる手法において,スレッドの割り当て方法には,OpenMPが有するschedule機能を用いて自動で設定する方法と,ユーザ側が手動で設定する方法がある.
図 6.4.2‑2(左)にOpenMPによる自動スレッド操作の例を示す.図中の赤字はOpenMPの指示文を表す.parallel指示文により,スレッドが生成される.通信処理(境界要素の収集・通信・展開)の前後にmaster指示文とend master指示文を挿入することで,スレッド0が通信処置を担当する.do指示文の指示句であるscheduleにdynamicを指定することで,各スレッドに演算処置が動的に割り当てられる.また,スレッド0の通信処理が終了した時点で演算処置が終了していなければ,スレッド0にも演算処置が割り当てられる.OpenMPによる自動スレッド操作はユーザ側の負担(プログラム修正)が小さいが,OpenMPによる操作のためのオーバヘッドが大きくなる問題がある.図 6.4.2‑2(右)に,OpenMPによる手動スレッド操作の例を示す.通信処理をスレッド0に割り当てる部分は自動スレッド割り当てと同じであるが,演算処理の各スレッドへの割り当てをOpenMPのdo指示文を使用せず,DO文に与える開始値と終了値に事前に計算しておいたスレッドごとの開始値と終了値を指定する.演算処理はスレッド0を除くスレッドで均等に分担し,均等に分担できなかった場合の、余りの処理をスレッド0が担当する.これは,本手法を適用する前提として,すべてのスレッドを演算に割り当ててもデータ供給が間に合わないメモリ負荷の高いアプリケーションを想定しているため,スレッド0には,通信処理と,最小限の演算処置を割り当てるためである.図6.4.2-2(右)の例では,MPIプロセスに割り当てられた領域の大きさ(DOループの繰り返し数)が100の場合のスレッドごとの開始値,終了値を示している.スレッド1~3の繰り返し数が33になるように分割され,あまりの1回の処理をスレッド0が行うように開始値,終了値が設定されている.このスレッド操作の場合,手動でスレッド操作を行うためOpenMPによるオーバヘッドの影響が小さい.事前に各スレッドに割り当てる演算の開始値と終了値を計算しておく必要があるが,わずか20行程度の処理の追加である.
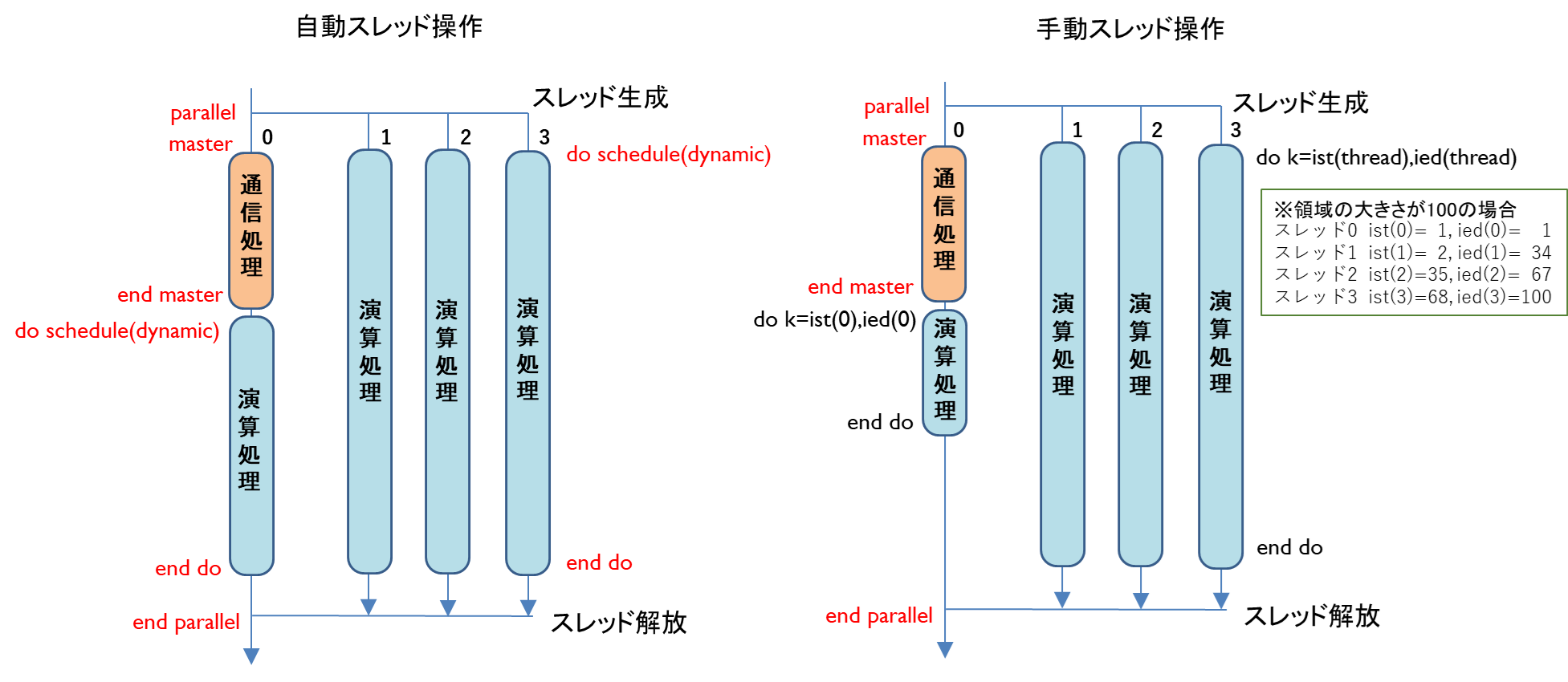
図 6.4.2‑2 OpenMPによる自動スレッド生成(左)と手動スレッド生成(右)¶
(2) 最適化内容¶
演算と通信のオーバーラップによる高速化事例を,Poisson方程式に対してSOR(Successive Over-Relaxation)法を用いて計算するプログラムを使用して説明する.図 6.4.2‑3(左)に演算と通信のオーバーラップ適用前,図 6.4.2‑3(右)に適用後のSOR法の処理フローを示す.
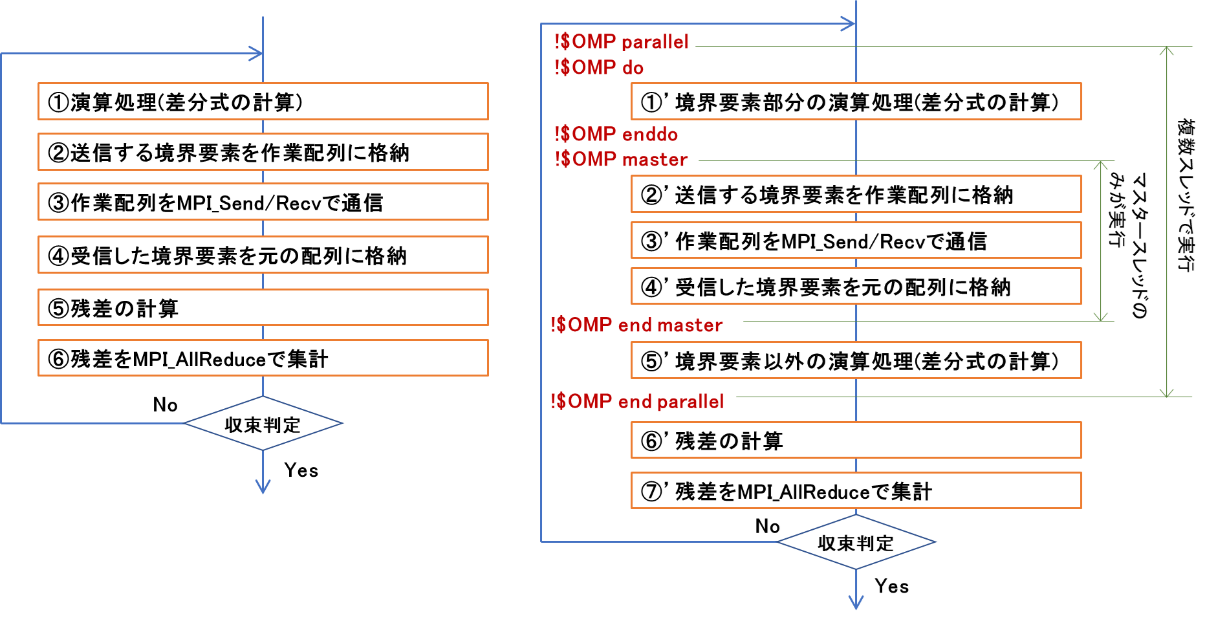
図 6.4.2‑3 オーバーラップ適用前(左)と適用後(右)のSOR法の処理フロー¶
まず,演算と通信のオーバーラップ前の処理フローでは,①で割り当てられた全領域の計算を行い,②③④では隣接するMPIプロセスが担当する境界要素の値を参照するため,MPI通信を用いてデータの転送を行う.②でメモリ上連続でないアドレスに格納されている境界要素を送信用の作業配列に連続して格納し,④で受信した作業配列を元の配列のアドレスに格納する処理を行う.⑤⑥でSOR法の収束判定のための処理を行っている.
次に,演算と通信をオーバーラップ後の処理フローでは,①’ の処理で,②’ ~ ④’ の送受信に使用する境界領域の計算を全スレッドで行う.②’ から ④’ の処理は前後に OpenMP指示文 master / end master を挿入することで,スレッド0のみで実行することを指定する.⑤’ の境界要素以外の演算処理の実装方法は図 6.4.2‑2に示した通り,自動スレッド操作と手動スレッド操作で異なる.図 6.4.2‑4に,手動スレッド操作の実装例を示す.OpenMPの指示文doを用いて,外側のKのループをスレッド並列化の対象にするが,schedule節を付加することでOpenMPが用意するループのスケジュールを使用する.schedule節のtypeにdynamicを指定すると動的なスケジュールが適用される.

図 6.4.2‑4 手動スレッド操作の例¶
図6.4.2‑5に手動スレッド操作時のスレッドに割り当てるループの開始値と終了値の計算例を示す.配列kst2に各スレッドのループの開始値,配列ked2に各スレッドのループの終了値を格納する.配列kst2,ked2は動的割り当て配列として,関数omp_get_num_threadsで取得した総スレッド数で配列サイズを定義する.スレッド1から最終スレッドにループを均等に割り当てるため,ループに余りが発生する場合にはスレッド0に割り当てる. 図6.4.2‑6に手動スレッド操作時の演算ループに対する処置を示す.手動スレッド操作では,あらかじめ計算しておいたスレッドごとのループの開始値と終了値を使用して各スレッドが担当するループを実行できるようにする.
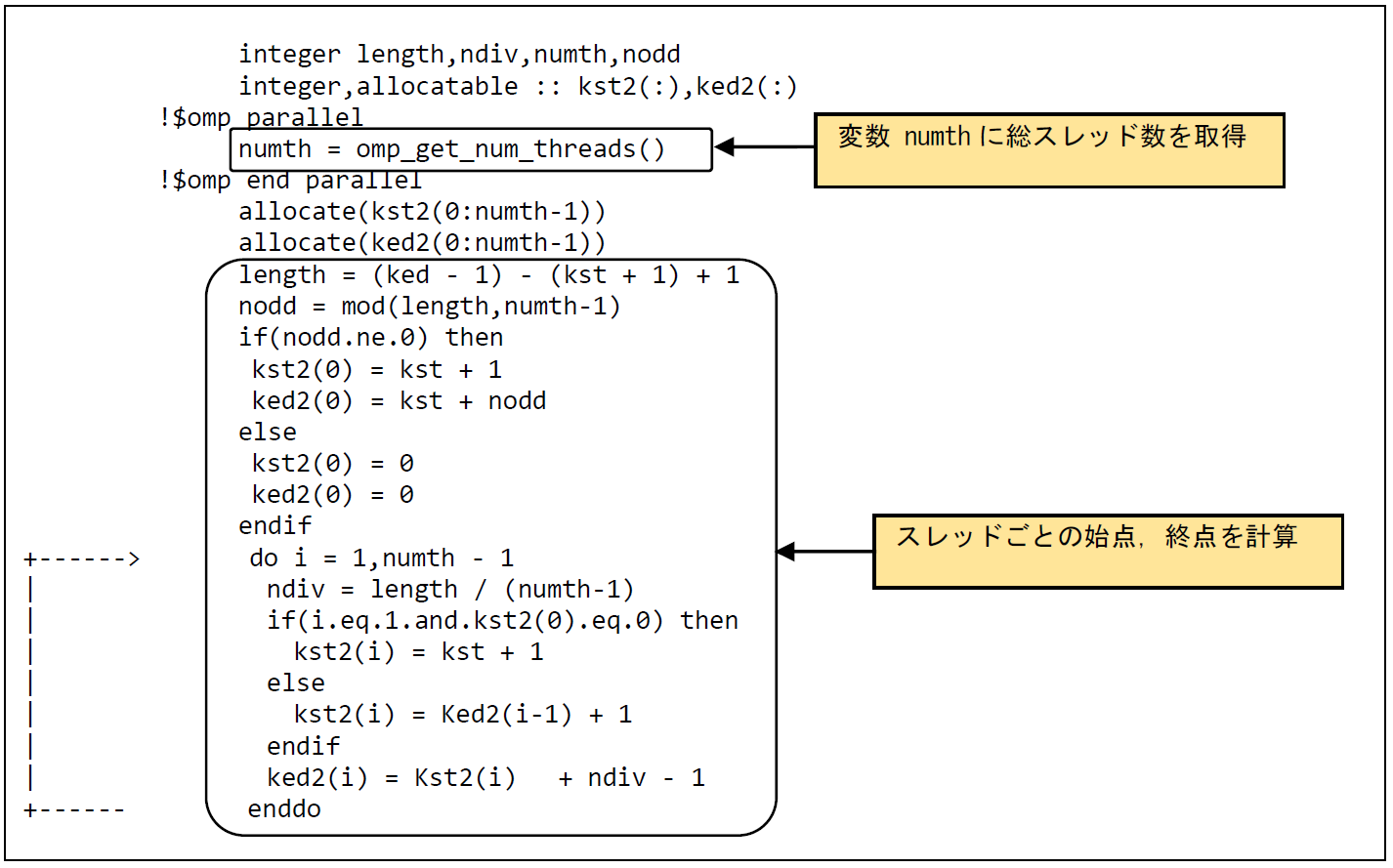
図 6.4.2‑5 手動スレッド操作の例(ループの始点・終点を求める)¶

図 6.4.2‑6 手動スレッド操作の例(演算ループに対する処置)¶
(3) 性能分析¶
図 6.4.2‑7にSOR法ループの測定結果を示す.オーバーラップなしの場合は,通信処置時間(Communucation Time)が2,059秒であり,全体時間から通信時間を除いた時間(Calculation Time)は2,222秒である.演算と通信のオーバーラップを適用し,かつ演算部分でOpenMPの自動スレッド操作を適用した自動スレッドオーバーラップの場合,全体実行時間が2,988秒となり,約1.5倍の性能向上が得られた.また,手動スレッド操作による手動スレッドオーバーラップの場合,OpenMPのオーバヘッドが削減されたことにより,自動スレッドオーバーラップよりもさらに実行時間が短縮された.
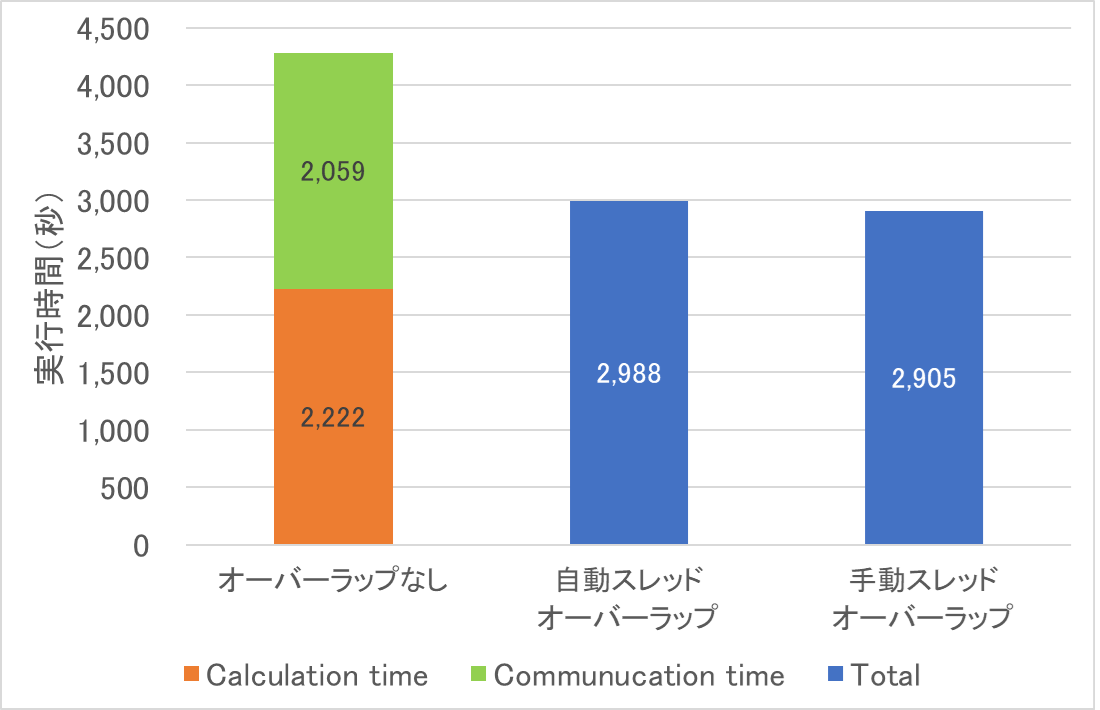
図 6.4.2‑7 SOR法ループの性能測定結果¶
6.5. VH-VEの連携による高速化の事例¶
6.5.1. VH Callによる高速化(1)¶
(1) 最適化方針¶
「5.3.1. VH Call」 に記載しているように,VEが不得意とする処理をVHにオフロードすることで性能を向上させることができる.本事例では,FortranコードをVH Callで高速化する方法を示す.
図 6.5.1‑1に,最適化前のFTRACE情報を示す.また,図 6.5.1‑2に最もコストの高いサブルーチンSUB_1の呼び出し構造の概要図を記載する.SUB_1は,MAIN関数から呼び出され,SUB_1自身も別のサブルーチンSUB_Aを呼び出している.さらに,SUB_AはSUB_1にインライン展開される構造をしている.サブルーチンSUB_1の性能情報(インライン展開されたSUB_Aの性能情報も含む)をみると,ベクトル演算率,平均ベクトル長がともに小さく,ベクトル処理に向いていないことがわかる.そこで,SUB_1配下の処理をVHにオフロードする.

図 6.5.1‑1 最適化前のFTRACE情報¶
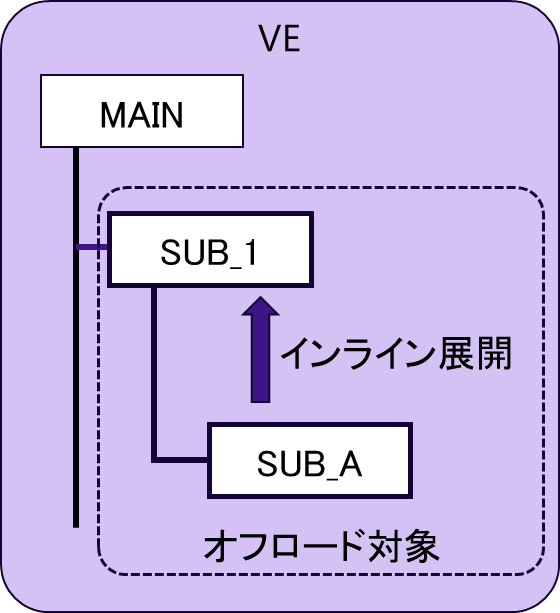
図 6.5.1‑2 サブルーチンSUB_1の呼び出し構造の概要図¶
(2) 最適化内容¶
図 6.5.1‑3に,VH Call適用後の実行イメージ図を記載する.VHにオフロードするサブルーチンを切り出し,共有ライブラリ libvhcal.soとしてコンパイルしておく.VE側のプログラムには,VH Callを利用するための手続き(fvhcall_install,fvhcall_findなど)を記載し,fvhcall_invoke_with_argsにより,VH側の処理をVE側から呼び出す.各手続きの概要については,「5.3.1 VH Call」を参照のこと.
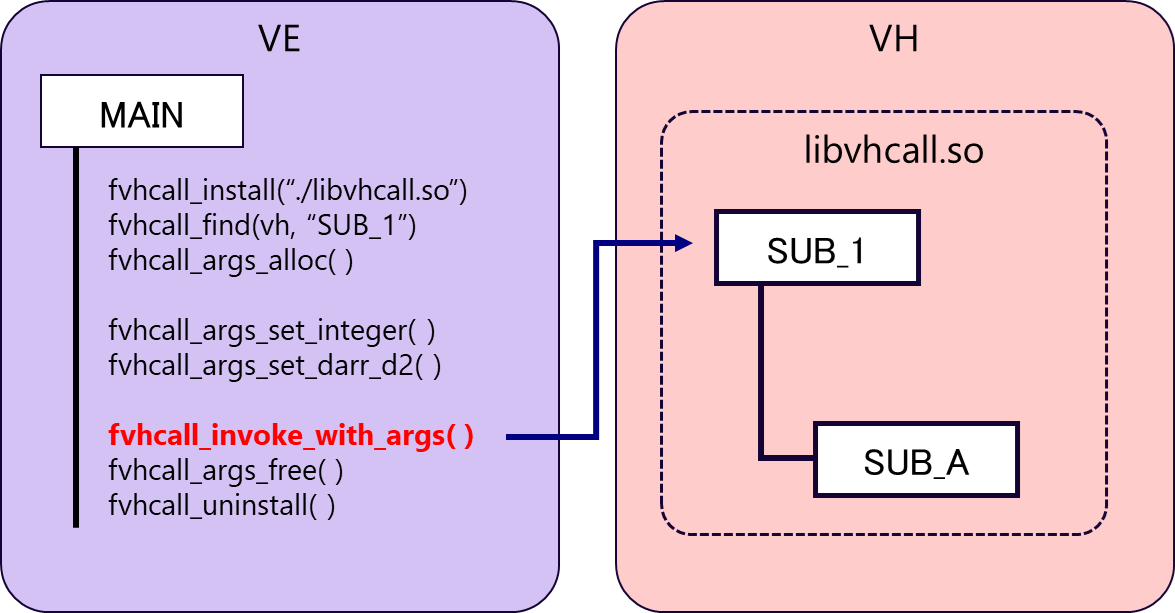
図 6.5.1‑3 VHcall適用後の実行イメージ図¶
図 6.5.1‑4に共有ライブラリlibvhcall.soのコンパイル方法を記載する.ソースコードvh_fortran.f90には,SUB_1およびSUB_Aを記載する.本事例では,GNUコンパイラを使用して共有ライブラリを作成している.
$ gfortran -shared -fPIC -o libvhcall.so vh_fortran.f90
図 6.5.1‑4 共有ライブラリのコンパイル方法
図 6.5.1‑5に,VE側で実行するコードのうち,VH Callに関連した部分を抜粋して記載する.まず,FortranプログラムでVH Callを使用するためには,vhcall_fortranモジュールを参照する必要があるため,use文でvhcall_fortranモジュール使用を宣言する.そして,fvhcall_installにより,作成した共有ライブラリ libvhcall.soを呼び出す.次に,vhcall_findにより,共有ライブラリの中からサブルーチンSUB_1を探す.その後,手続きに渡す引数を作成するため,fvhcall_args_alloc ,fvhcall_args_set_XXXXを実行する.ここで,XXXXの部分は,引数の型によって変わり,必要な引数の数だけ記載する必要がある.この事例では,2つの単精度整数型の変数,int1およびint2,倍精度実数型の2次元配列array1,倍精度実数型の3次元配列array2の4つの引数を設定している.fvhcall_intent_inが,指定されている場合,その引数がVH側で実行されるライブラリへの入力として扱われ,fvhcall_intent_outが指定されている場合,その引数は出力となる.入力,出力の両方になる場合には,fvhcall_intent_inoutを指定する.引数の設定後,VH側の手続きを呼びだすためにfvhcall_invoke_with_argsを実行する.VH上での処理が完了すると,fvhcall_args_freeによって引数を開放し,fvhcall_args_uninstallで共有ライブラリをアンロードする.

図 6.5.1‑5 VE側で実行するコード¶
(3) 性能分析¶
表 6.5.1‑1に,最適化前後のサブルーチンSUB_1(SUB_Aの実行時間も含む)の実行時間を記載する.
表 6.5.1‑1 最適化前後のSUB_1(SUB_Aを含む)の実行時間

VHCallにより処理をVH側にオフロードすることで,実行時間が49.6秒から21.3秒に短縮された.
6.5.2. VH Callによる高速化(2)¶
(1) 最適化方針¶
「6.5.1. VH Callによる高速化(1)」ではFortranプログラムでVH Callを使用した高速化の事例を紹介したが,ここではC++コードにVHcallを適用した事例を示す.
図 6.5.2‑1に,本プログラムの時間発展ループの概念図を示す.Main関数内の時間発展ループでは複数の関数が実行されるが,FUNC_2及びFUNC_3はベクトル化できない処理を含んでいる.図 6.5.2‑2にFUNC_2,FUNC_3の実行時間,平均ベクトル長,ベクトル演算率を記載する.FUNC_2とFUNC_3を合わせた実行時間は,全体の約7割を占めていることがわかる.さらに,これらの処理のベクトル演算率,平均ベクトル長は小さく,VH側にオフロードして実行することで実行時間の短縮が期待できる. そこで,FUNC2,FUNC3をVHにオフロードする.
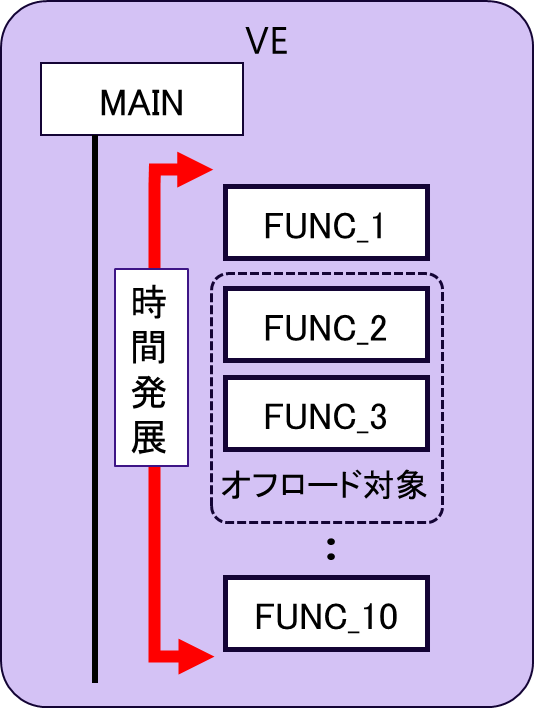
図 6.5.2‑1 時間発展ループの概念図¶

図 6.5.2‑2 最適化前のFTRACE情報¶
(2) 最適化内容¶
図 6.5.2‑3に,VH Call適用後の実行イメージ図を記載する.FUNC_2内で生成されるデータは,FUNC_3でしか使用されないため,FUNC_2とFUNC_3を1つの関数FUNC_23としてまとめることで,VE-VH間の通信量を削減している.VE側のプログラムでは,VH Call利用のための前準備(共有ライブラリの呼び出し,引数の作成など)を行い,vhcall_invoke_with_argsにより,VH側の処理を呼び出す.
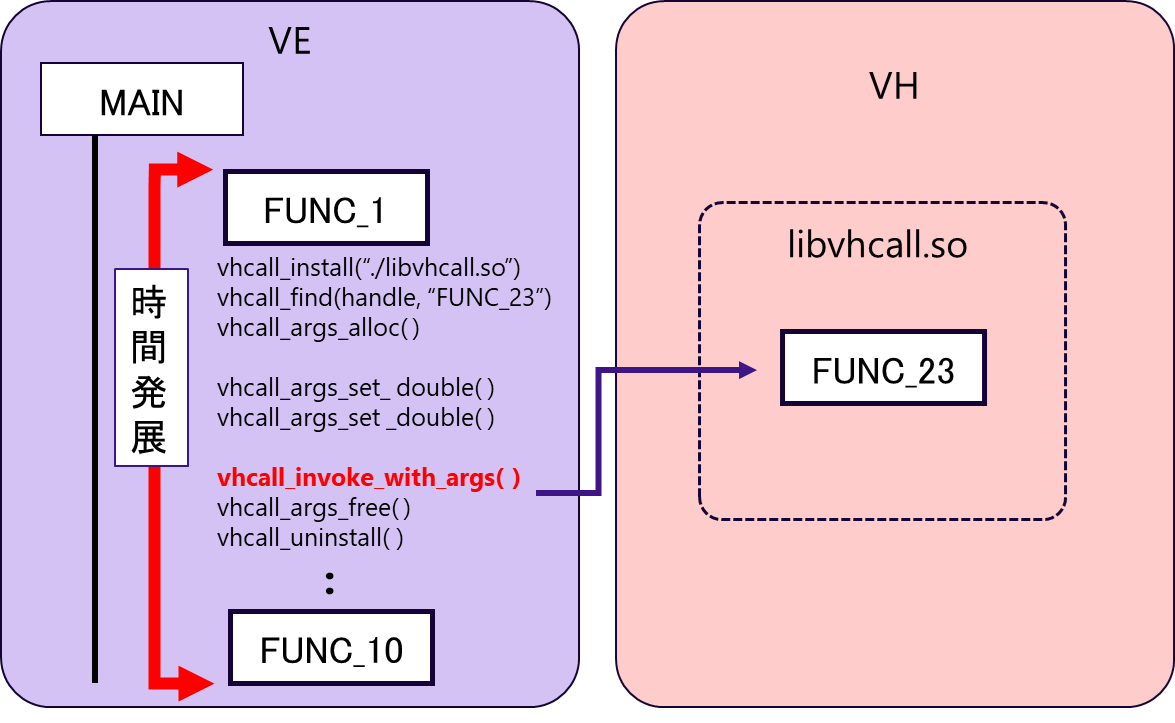
図 6.5.2‑3 VHcall適用後の実行イメージ図¶
FortranプログラムのVHcallと同様に,C++プログラムにおいても,VHで利用可能なコンパイラを使用して共有ライブラリのコンパイルを行う.図 6.5.2‑4に,共有ライブラリlibvhcall.soのコンパイル方法を記載する.vh.cppには,FUNC_2,FUNC3の処理をまとめたFUNC_23が記載されている.本事例では,GNUコンパイラを使用して共有ライブラリを作成している.
$ g++ -Ofast -march=native -fopenmp -I include -shared -o libvh.so -std=c++11 -fPIC vh.cpp
図 6.5.2‑4 共有ライブラリのコンパイル方法
図 6.5.2‑5に,VE側で実行するコードのうち,VH Callに関連した部分を抜粋して記載する.まず,C/C++プログラムでVHcallを使用するために,#includeディレクティブにより,ヘッダファイルlibvhcall.hを読み込む.そして,vhcall_installにより,作成した共有ライブラリ libvhcall.soを呼び出す.次に,vhcall_findにより,共有ライブラリの中から関数FUNC_23を探す.関数への引数の引き渡しは,vhcall_args_alloc,vhcall_args_set_XXXXにより行われる.ここで,XXXXは引数により異なり,記載された例では,倍精度浮動小数点型の変数double1,4バイト符号付き整数型の変数int1, 4バイト符号なし整数型の変数u_int1,8バイト符号なし整数型の変数u_long1,ポインタptr1 となっている.vhcall_args_set_pointerで指定されているVHCALL_INTENT_OUTは,その引数が,VH側で実行される関数からの出力であることをあらわす.引数がVH側で実行される関数への入力になる場合には,VHCALL_INTENT_INを,入出力になる場合には,VHCALL_INTENT_INOUTを指定する.引数の設定後,VH側の関数を呼び出すために vhcall_invoke_with_argsを実行する.VH上での処理が完了するとvhcall_args_freeによって引数を開放し,vhcall_args_uninstallで共有ライブラリをアンロードする.
!VE側で実行するコード
:
#include <libvhcall.h>
:
static vhcall_handle handle = vhcall_install("./libvhcall.so");
static int64_t symid = vhcall_find(handle, "FUNC23");
int ret;
vhcall_args *ca = vhcall_args_alloc();
ret = vhcall_args_set_double(ca, 0, double1);
:
ret = vhcall_args_set_i32(ca, 6, int1);
:
ret = vhcall_args_set_u32(ca, 9, u_int1);
:
ret = vhcall_args_set_u64(ca, 10, u_long1);
:
ret = vhcall_args_set_pointer(ca, VHCALL_INTENT_OUT, 19, ptr1, sizeof(int) * n);
:
ret = vhcall_invoke_with_args(symid, ca, NULL);
:
vhcall_args_free(ca);
vhcall_uninstall(handle);
}
:
図 6.5.2‑5 VE側で実行するコード
(3) 性能分析¶
表 6.5.2‑1に,最適化前後の関数FUNC_1およびFUNC_2の実行時間を記載する.
表 6.5.2‑1 最適化前後のFUNC_1およびFUNC_2の実行時間

VHCallにより処理をVH側にオフロードすることで,実行時間が44.812秒から19.005秒に短縮された.
6.5.3. VH-VE Hybrid MPI による高速化¶
(1) 最適化方針¶
物理現象の時間発展の様子を計算するシミュレーションでは,特定のタイムステップごとに,計算結果をファイルに出力し,後処理において時間変化の様子を確認することがよくある.ファイル出力の間隔を短くすればするほど,現象の時間発展の様子をより短い時間間隔で解明することができる.しかし,ファイル出力の回数が増える分,ファイルI/Oのコストも増加する.特に,1回あたりの出力ファイルのサイズが大きい場合には,プログラム全体に占めるI/O時間の割合が無視できないくらいに大きくなる場合もある.本事例は,VE-VH Hybrid MPIにより,ファイルI/Oにかかる時間を削減した事例である.
本事例のプログラムは,自然現象の時間発展の様子をリアルタイムに予測計算するものであり,入力データを一定の時間間隔で受信するという特徴がある.つまり,次の入力データを受信するまでに,シミュレーションを完了させなければならないという制約がある.
図 6.5.3‑1に本プログラムの全体概要図を記載する.入力データの受信インターバルは30分であり,この間に,7時間分の物理シミュレーションを実行する.オリジナルの実行条件では,1時間分のシミュレーションごとにファイル出力が行われ,1回あたり160MBのファイルを4ファイル出力する. 図 6.5.3‑2は,最適化前のプログラム全体の実行時間を示している.1時間に1回ファイル出力を行うケースで,すでに制限時間の30分ぎりぎりの値となっており.ファイルの出力間隔を短くすると制限時間を超過してしまうことがわかる.
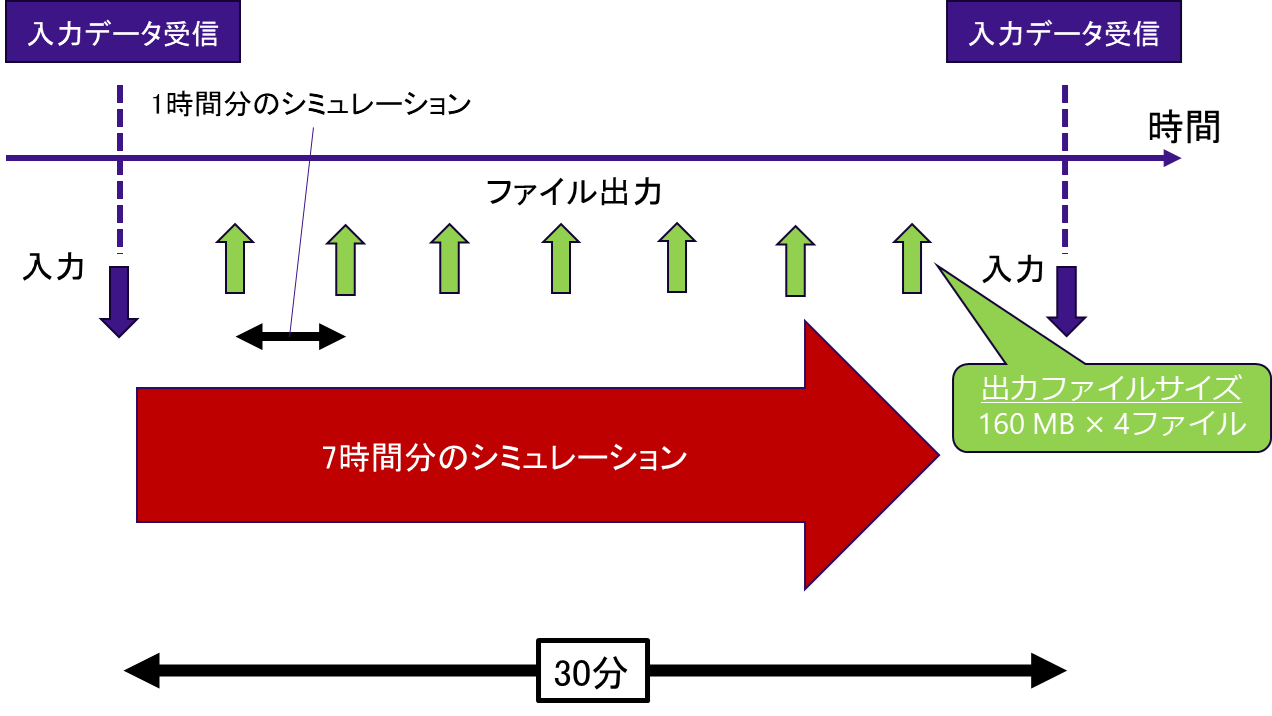
図 6.5.3‑1 プログラムの全体概要図¶
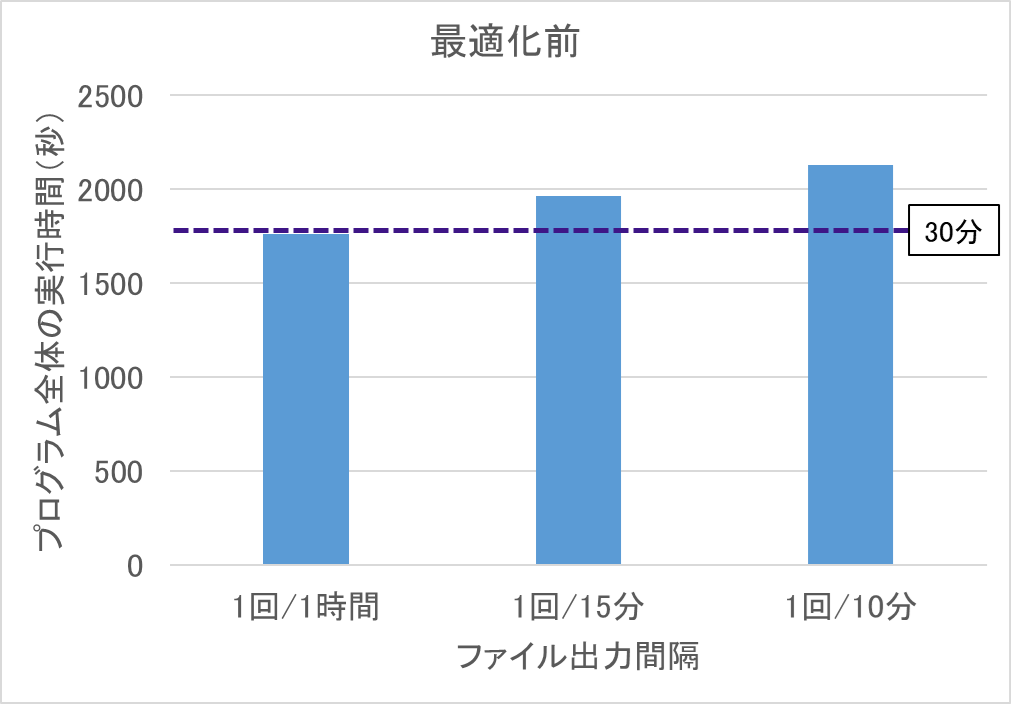
図 6.5.3‑2 最適化前のプログラム全体の実行時間¶
(2) 最適化内容¶
ファイル出力処理の実行時間を削減するために,VH上にファイル出力処理を行うMPIプロセスを立ち上げる.ファイル出力処理を行うI/Oプログラムを新規に作成し(VH application),VE上で主要演算を行うプログラム(VE application)と連携させる.図 6.5.3‑3にVE applicationコードを記載する.まず,VH上のMPIプロセスとVE上のMPIプロセスのデータのやり取りは,すべてのMPIプロセスが所属するコミュニケータ(mpi_comm_world)を使用して行われる.次に,mpi_comm_split でmpi_comm_worldを分割し,VE上で動作するMPIプロセス間での通信を制御するためのコミュニケータ(mpi_comm_ve)を生成する.VE上で主要演算を行うMPIプロセス間の通信は,このmpi_comm_veを使用して行われる. ファイル出力に必要なパラメータ(ny,nx,t)および出力データ(data)は1対1通信であるmpi_sendを使用して転送している.この事例では,double precision型の配列dataに格納されたny * nx 個のデータが,VH上で動作するプロセスに送信される.簡単のために1ファイル分の出力の例を抜粋して記載しているが,実際には4ファイル分の転送処理が行われる.図 6.5.3‑4にはVH applicationコードを記載する.VH applicaionでは,VH,VE上の全プロセスが所属するコミュニケータであるmpi_comm_worldを使用して,VEからmpi_secdにより送信されたパラメータ,データをmpi_recvで受信している.データの受信が完了すると,受信したデータの出力処理を行う.VH applicationの終了判定は,終了フラグにより制御する.VE applicationでは,すべての計算処理完了後,-1にメッセージタグ3をつけてVH applicationに送信している.VH applicationではメッセージタグ3のついたデータをパラメータ t として受信し,t の値が -1 の場合にプログラムを終了するようにしている.
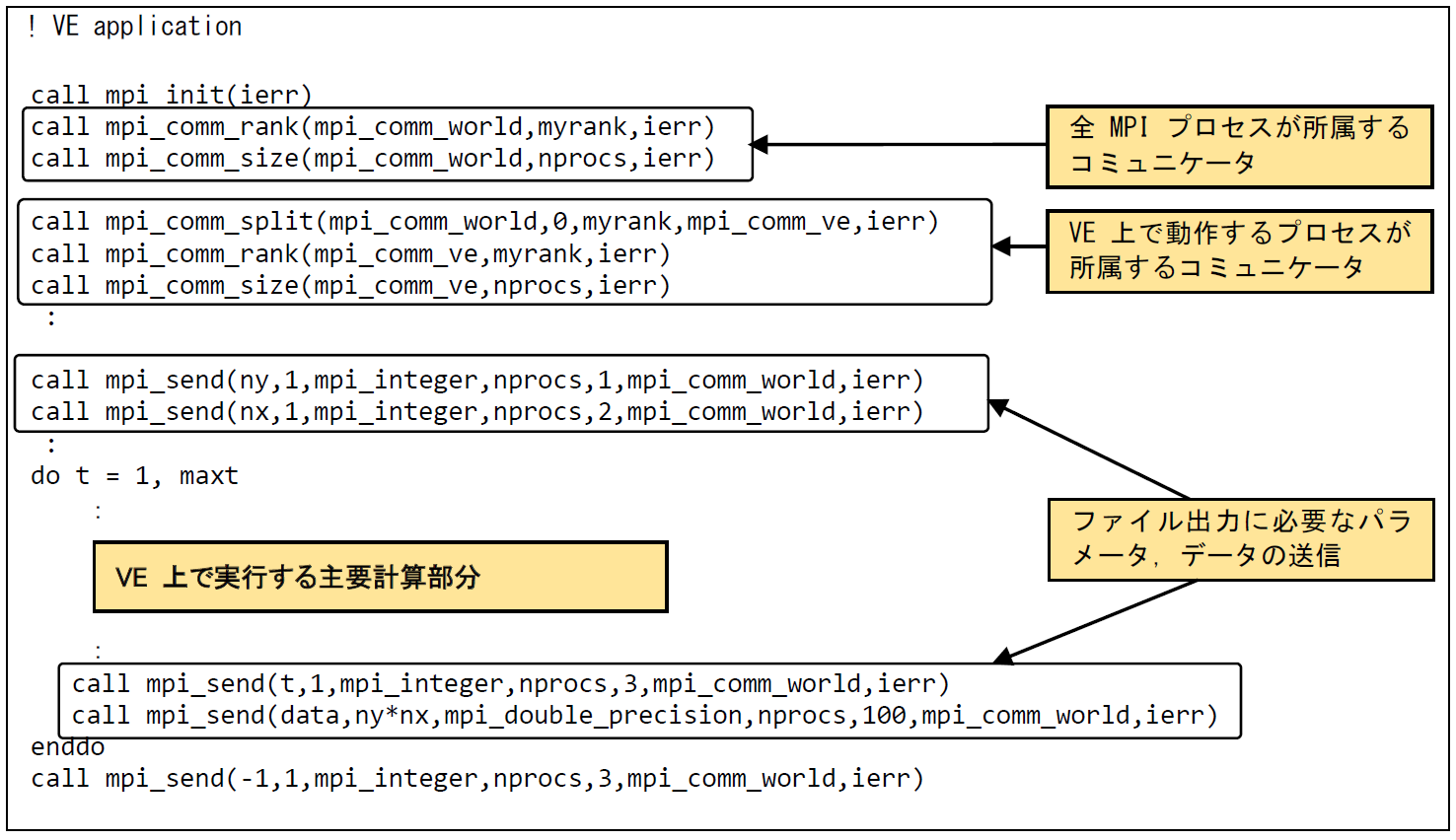
図 6.5.3‑3 VE application コード¶
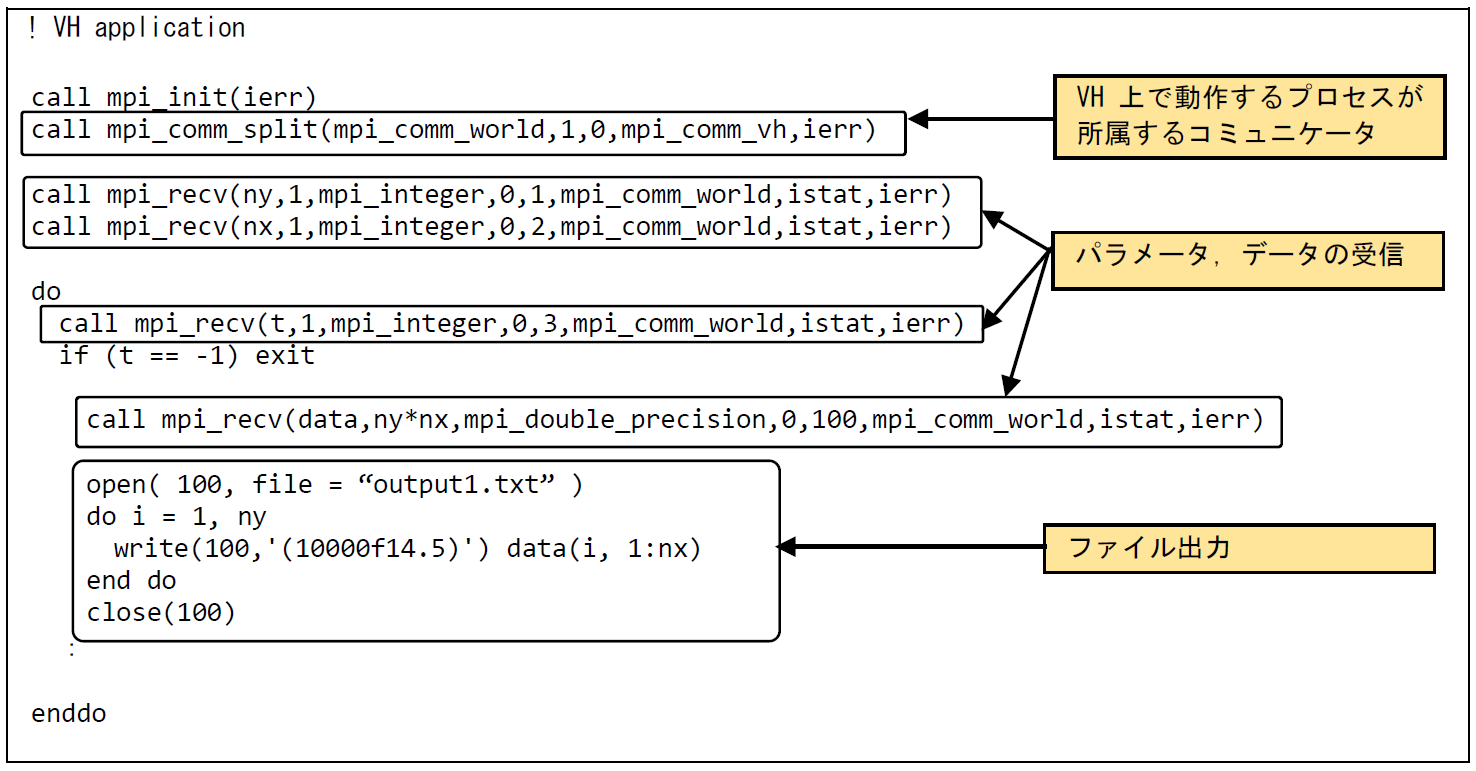
図 6.5.3‑4 VH application コード¶
(3) 性能分析¶
図 6.5.3‑5に最適化前後のプログラム全体の実行時間を示す.

図 6.5.3‑5 最適化前後のプログラム全体の実行時間¶
ファイル出力処理がVH側で実行され,さらに,VE側の演算処理とVH側のI/O処理がオーバーラップ可能になったことで,1時間に1回出力のパターンにおいてもプログラム全体の実行時間が短縮されている.さらに,ファイル出力間隔を短くして,ファイルの出力回数を増やしても,最適化後では,プログラム全体の実行時間はほとんど変化しておらず,制限時間内にプログラムを完了させることが可能になっていることがわかる.