4. 大規模科学計算システムの構成¶
スーパーコンピューティング研究部 滝沢寛之 高橋慧智 下村陽一
情報部デジタルサービス支援課 大泉健治 小野敏 山下毅 齋藤敦子 森谷友映
高性能計算技術開発(NEC)共同研究部門 撫佐昭裕 磯部洋子 曽我隆 山口健太
日本電気株式会社 加藤季広
NECソリューションイノベータ株式会社 佐藤佳彦
本センターでは,2020年10月よりスーパーコンピュータシステムAOBAの運用を開始した.AOBAはサブシステムAOBA-A(SX-Aurora TSUBASA B401-8)およびサブシステムAOBA-B(LX 406Rz-2)の2種類の計算機システムと,ストレージシステムで構成される.ストレージシステムは,高速かつ高密度ストレージであるDDN SFA7990XEを導入している.ファイルシステムは,NEC製の分散・並列ファイルシステムである Scalable Technology File System(ScaTeFS)で構成され,実効容量2PBのユーザホーム領域を提供している.さらに,2022年10月からは,計算機資源の増強のために期間限定でクラウドサービスAOBA-C(SX-Aurora TSUBASA B302-8)の提供を開始した. 図 4‑1に,2022年10月時点における本センターのシステム構成を示す.
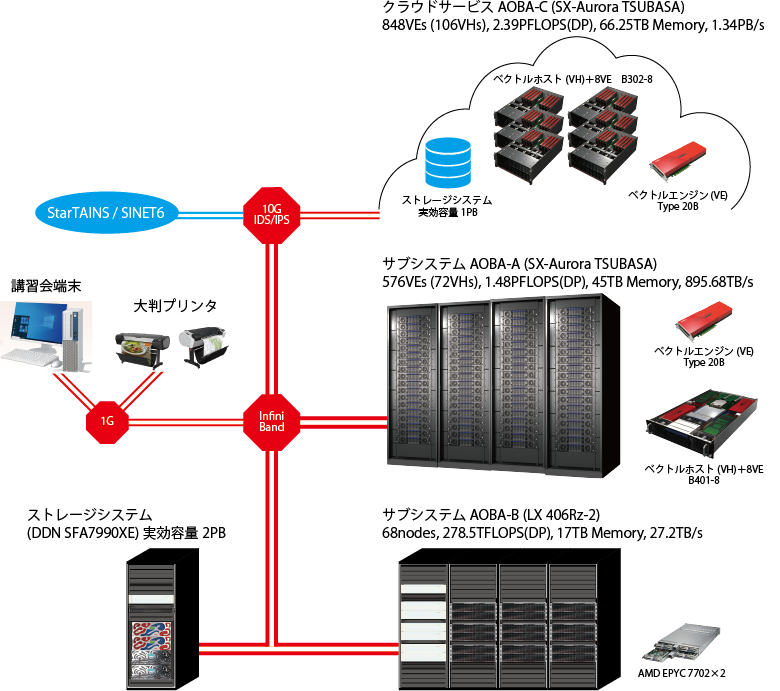
図 4‑1 2022年10月時点におけるシステム構成¶
さらに,2023年8月からはサブシステムAOBA-S(SX-Aurora TSUBASA C401-8)の運用が開始された.AOBA-SはSX-Aurora TSUBASAの最新機種であるVE30を搭載しており,AOBA-Aの7倍となる504VHで構成されている.図 4‑2に2023年8月時点におけるシステム構成を示す.AOBA-Sの運用開始に伴い,クラウドサービスであるAOBA-Cの運用は終了した.
AOBA-SはAOBA-A, AOBA-Bとは独立したシステムとして運用されている.利用者はAOBA-S用のフロントエンドサーバにログインし,AOBA-Sにジョブを投入する.AOBA-S用のストレージシステムとして DDN ES400NVX2 を新たに導入した.ファイルシステムは分散並列ファイルシステムであるLustreを採用しており,実効容量は4.5 PBとなる.
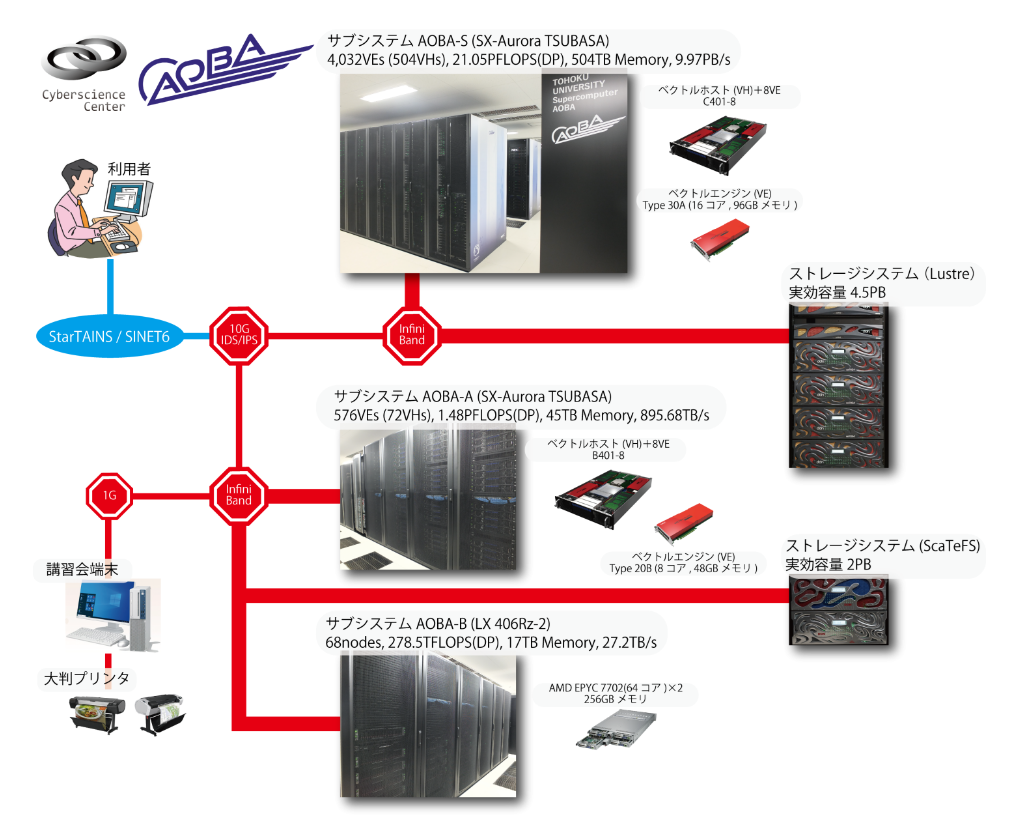
図 4‑2 2023年8月時点におけるシステム構成¶
4.1. AOBA-A, AOBA-CおよびAOBA-Sの特徴¶
AOBA-A,AOBA-CおよびAOBA-Sを構成するSX-Aurora TSUBASAはVector Engine(以降VE)と呼ばれるPCI Express カードにベクトルプロセッサと主記憶を搭載し,これをVector Host(以降VH)と呼ばれる標準的なx86サーバに接続することにより構成されている.AOBA-AおよびAOBA-Cは第二世代のVE(Type 20B)を搭載しており,AOBA-Sは2023年8月時点で最新の第三世代のVE(Type 30A)を搭載している.システムの主な諸元を表 4.1‑1に示す.
表 4.1‑1 AOBA-A, AOBA-CおよびAOBA-Sの主要諸元

4.1.1. VH-VE構成¶
ここでは,現在運用中のAOBA-AとAOBA-SのVH-VE構成について概説する.
図 4.1.1‑1にAOBA-AのVH-VE構成(左)とVE(Type 20B)のブロック図(右)を記載する.AOBA-Aの構成要素であるSX-Aurora TSUBASA B401-8はVHと,8枚のVEで構成される.VHのプロセッサはAMD EPYC 7402Pであり1socket 24コアを備えている.プロセッサは4つのPCI Express Switch(PCIe SW)と2つのInfiniBand HCAカード(IB HCA)と直接接続されている.PCIe SWはそれぞれ2つのVEと接続されており,VEは8個のCPUコアと,コア間で共有されるLLC(Last Level Cache),6個のHBM2メモリで構成される.
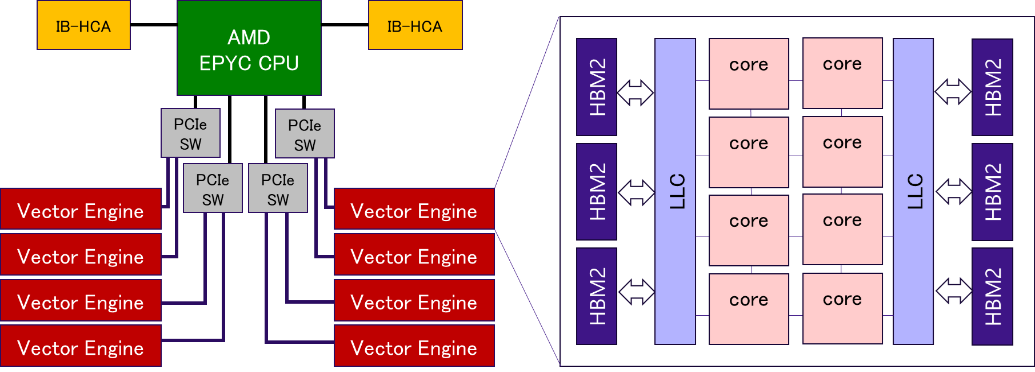
図 4.1.1‑1 AOBA-AのVH-VE構成の概要図¶
図 4.1.1‑2にAOBA-SのVH-VE構成(左)とVE(Type 30A)のブロック図(右)を記載する.AOBA-SのVHのプロセッサはAMD EPYC 7763であり1socket 64コアを備えている.AOBA-Aと同様に,プロセッサは4つのPCIe SWを介して8つのVEと接続されている.VEは16個のCPUコア,LLC,6つのHBM2Eメモリで構成され,AOBA-AのVE(Type 20B)と比較して,CPU数は2倍,LLCの容量は4倍,メモリ容量は2倍の増加となる.性能向上としては,VEあたりの理論演算性能は2倍,LLCの帯域幅は2.13倍,メモリ帯域幅は1.6倍となる.さらに,それぞれのCPUコアには新しく2MBのL3キャッシュ(L3C) が導入されている.L3キャッシュにキャッシュするデータはソフトウェア制御(指示行の挿入)によりユーザ側で指定することができるため,キャッシュ容量を効率的に利用することができる.このようなメモリシステムの大幅な改善により,メモリ負荷の高いアプリケーションの性能が大幅に改善することが期待される.さらに,VE(Type 30A)では,パックドベクトル命令利用時のデータアラインメント制限の緩和,間接参照によるベクトル総和演算をLLC上の専用ハードウェアで実行するVLFA命令の追加といった改善も加わっている.
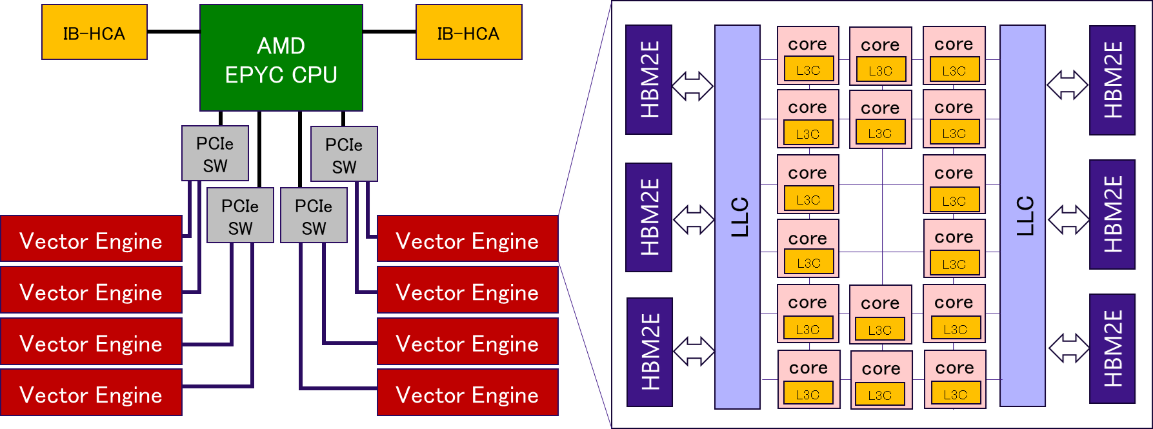
図 4.1.1‑2 AOBA-SのVH-VE構成の概要図¶
4.1.2. マルチノード構成¶
図 4.1.2‑1にAOBA-Aのマルチノード構成図を記載する.AOBA-Aは72台のVHで構成され,InfiniBand HDRによる2段Fat Treeネットワークにより接続される.フルバイセクションバンド幅,ノンブロッキング構成によりすべてのVH,ストレージ,周辺サーバ群で高速な通信が可能となる.
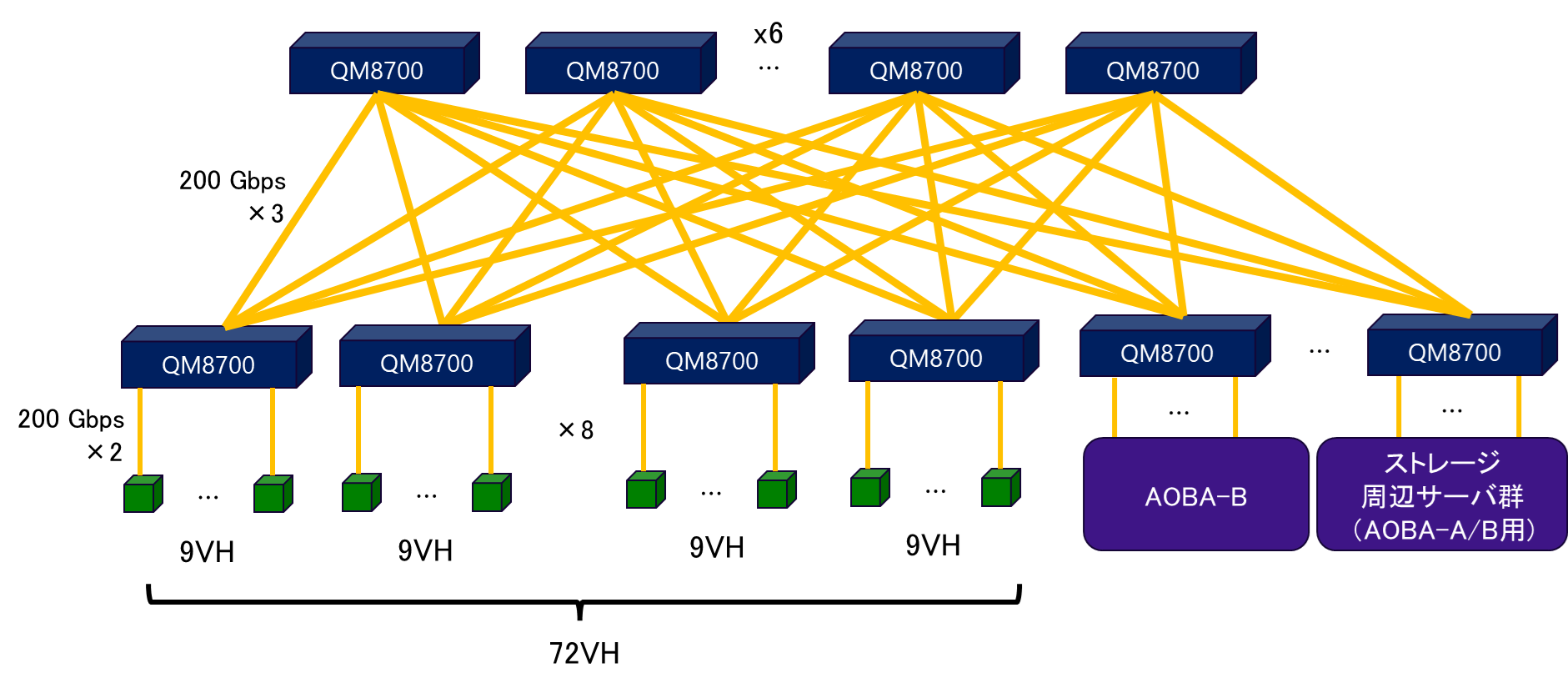
図 4.1.2‑1 AOBA-Aのマルチノード構成図¶
図 4.1.2‑2にAOBA-Sのマルチノード構成図を記載する.AOBA-Sは504台のVHで構成される.AOBA-Aと同様にノード間接続ネットワークは2段Fat Tree構成となっている.それぞれのVHは2つのIB HCAを搭載しており,InfiniBand NDR200 によりノード間ネットワークに接続される.ネットワークスイッチ間はInfiniBand NDRにより接続され,フルバイセクションバンド幅,ノンブロッキング構成でVHと接続される.AOBA-S用のストレージや周辺サーバ群もこのネットワークに接続されており,VHとストレージ間での高速なデータ転送が可能となる.
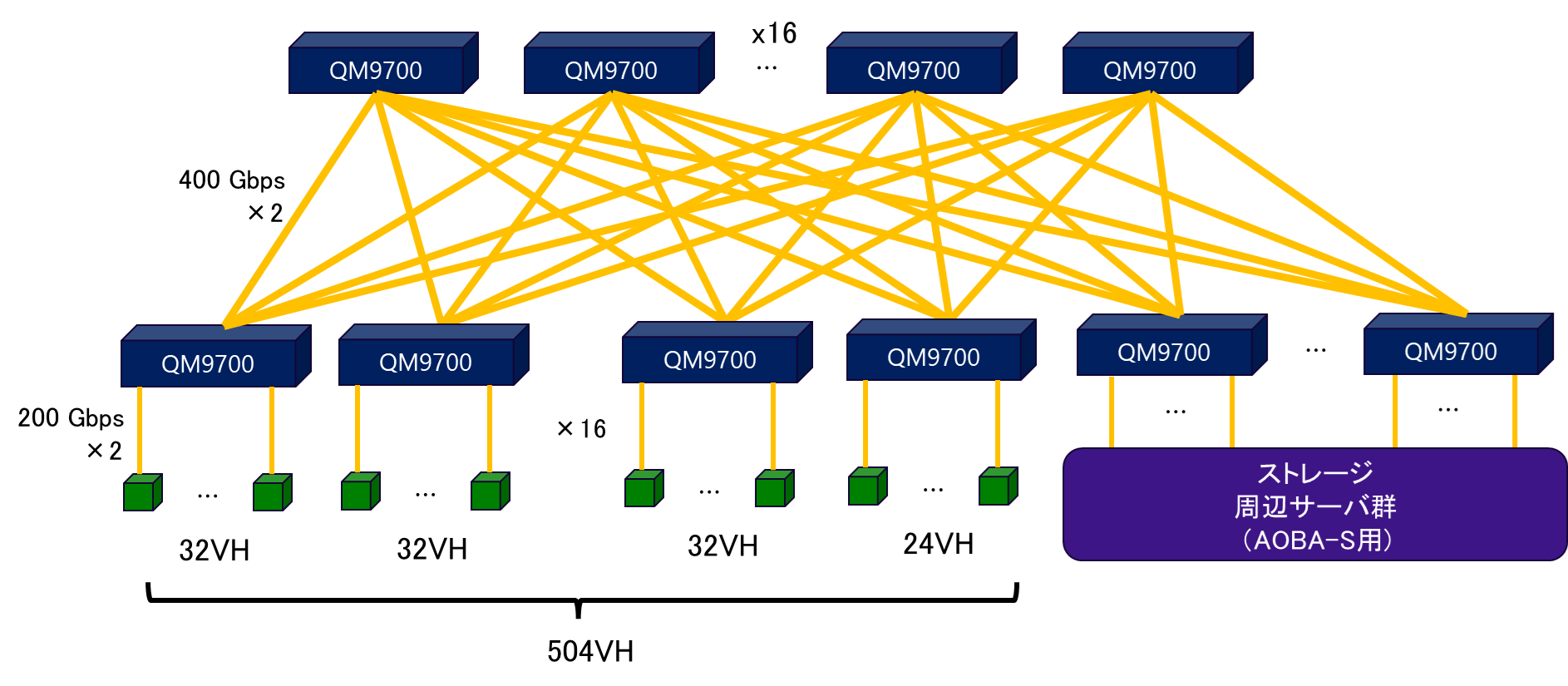
図 4.1.2‑2 AOBA-Sのマルチノード構成図¶
4.2. AOBA-Bの特徴¶
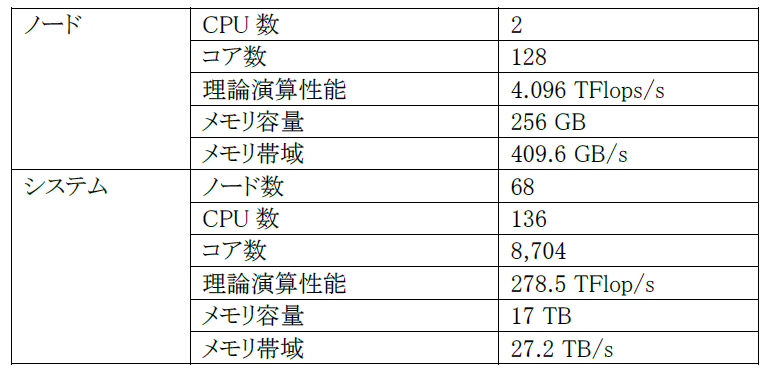
AOBA-BはLX406Rz-2で構成される.LX406Rz-2は,1ノードにAMD EPYC 7702(64コア)を2基と,256GBの主記憶を搭載している.本センターでは,68ノードのLX406Rz-2を運用しており,総理論演算性能278.5TFlop/s,総メモリ容量は17TBを有している.システムの主な諸元を表 4.2‑1に示す.
表 4.2‑1 LX406Rz-2の主要諸元
4.2.1. ノード構成¶
図 4.2.1‑1に,LX407Rz-2のノード構成を示す.LX406Rz-2は,AMD EPYC 7702プロセッサを2基搭載している.プロセッサあたり64コアが搭載されており,プロセッサ間は4チャネルのxGMI(inter-chip Global Memory Interconnect)インタフェースで接続されている.プロセッサあたり8チャネルのDDR4-3200対応メモリインタフェースを装備しており, 16GB DIMMを使用することでノードあたり256GBのメモリ容量を実装している.メモリバンド幅は1チャネルあたり25.6GB/sであり,ノード全体では409.6GB/sとなる.
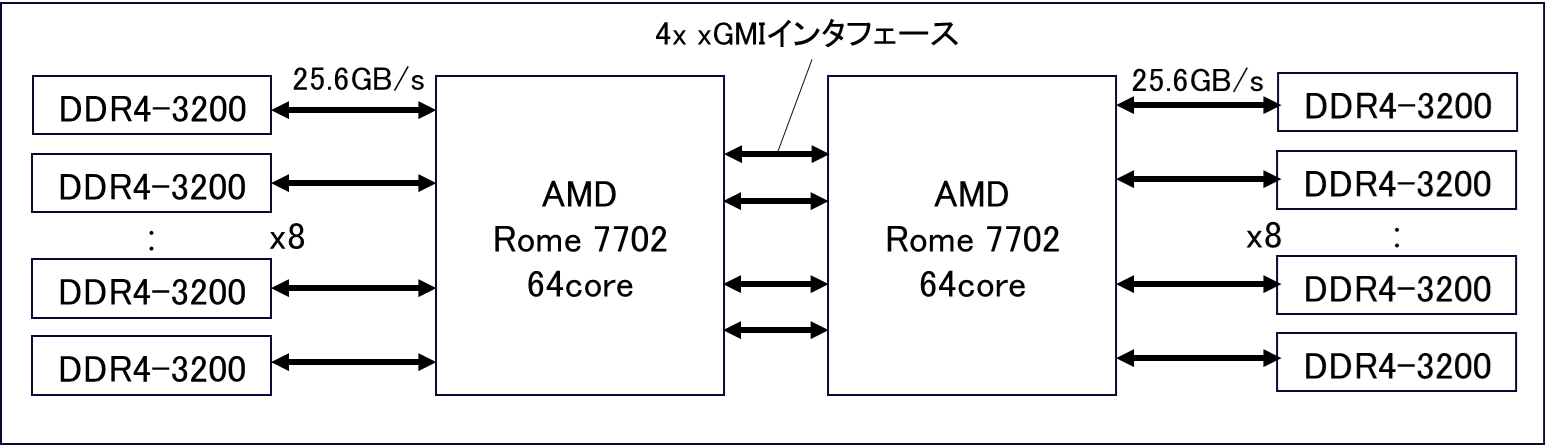
図 4.2.1‑1 LX406Rz-2のノード構成図¶
4.2.2. マルチノード構成¶
図 4.2.2‑1にLX406Rz-2のマルチノード構成図を示す.AOBA-Aと同様にInfiniBand HDRによる2段Fat-Treeネットワークによりノード間が接続されており,フルバイセクションバンド幅,ノンブロッキング構成によりすべての演算サーバ,ストレージ,周辺サーバ群で高速な通信が可能となる.全ノードを使用することで最大8,704コアを使用したマルチノードプログラムの実行が可能である.ただし,センターの通常運用においては,最大利用可能ノード数は16ノードまでとしているため,1ジョブあたり最大2,048コアが利用可能である.
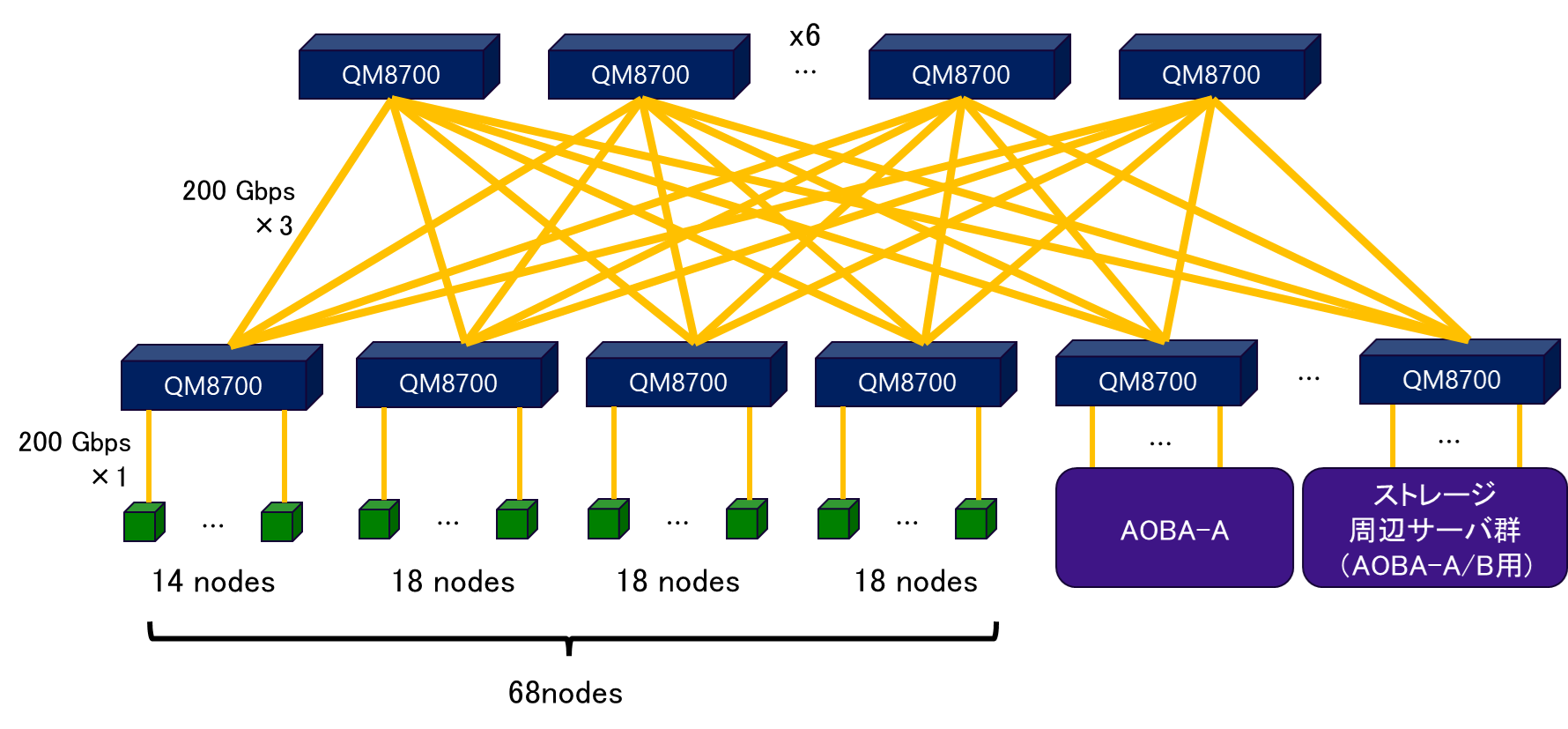
図 4.2.2‑1 LX406Rz-2のマルチノード構成図¶